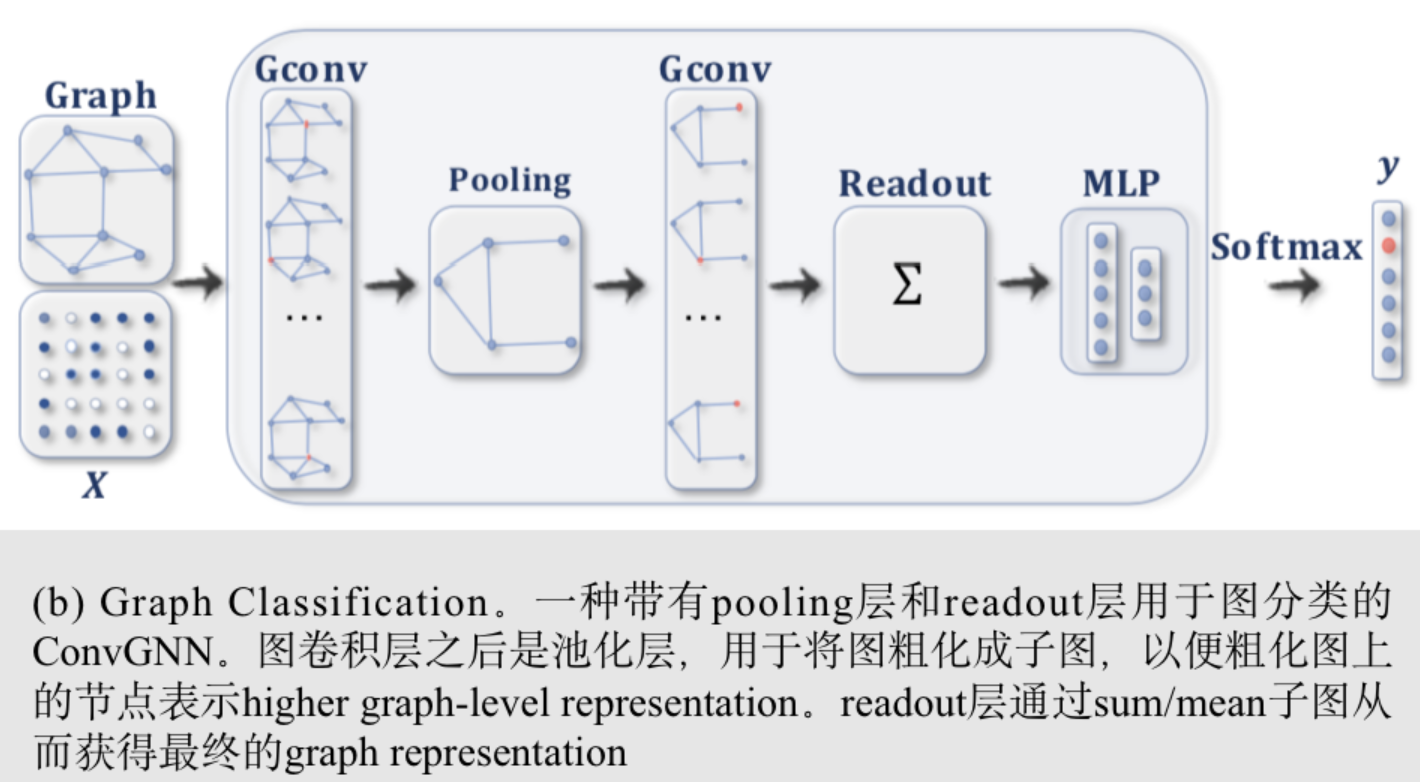
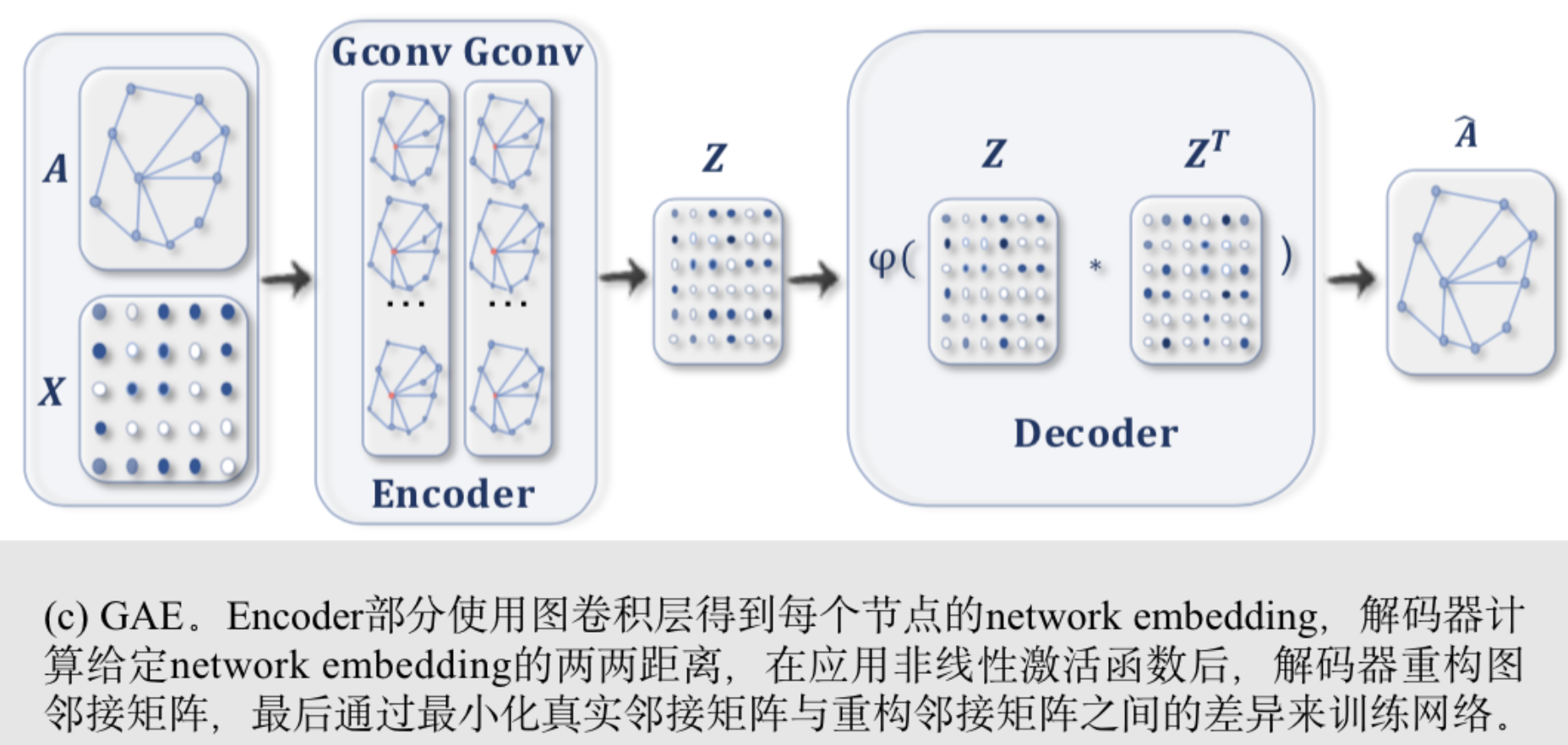
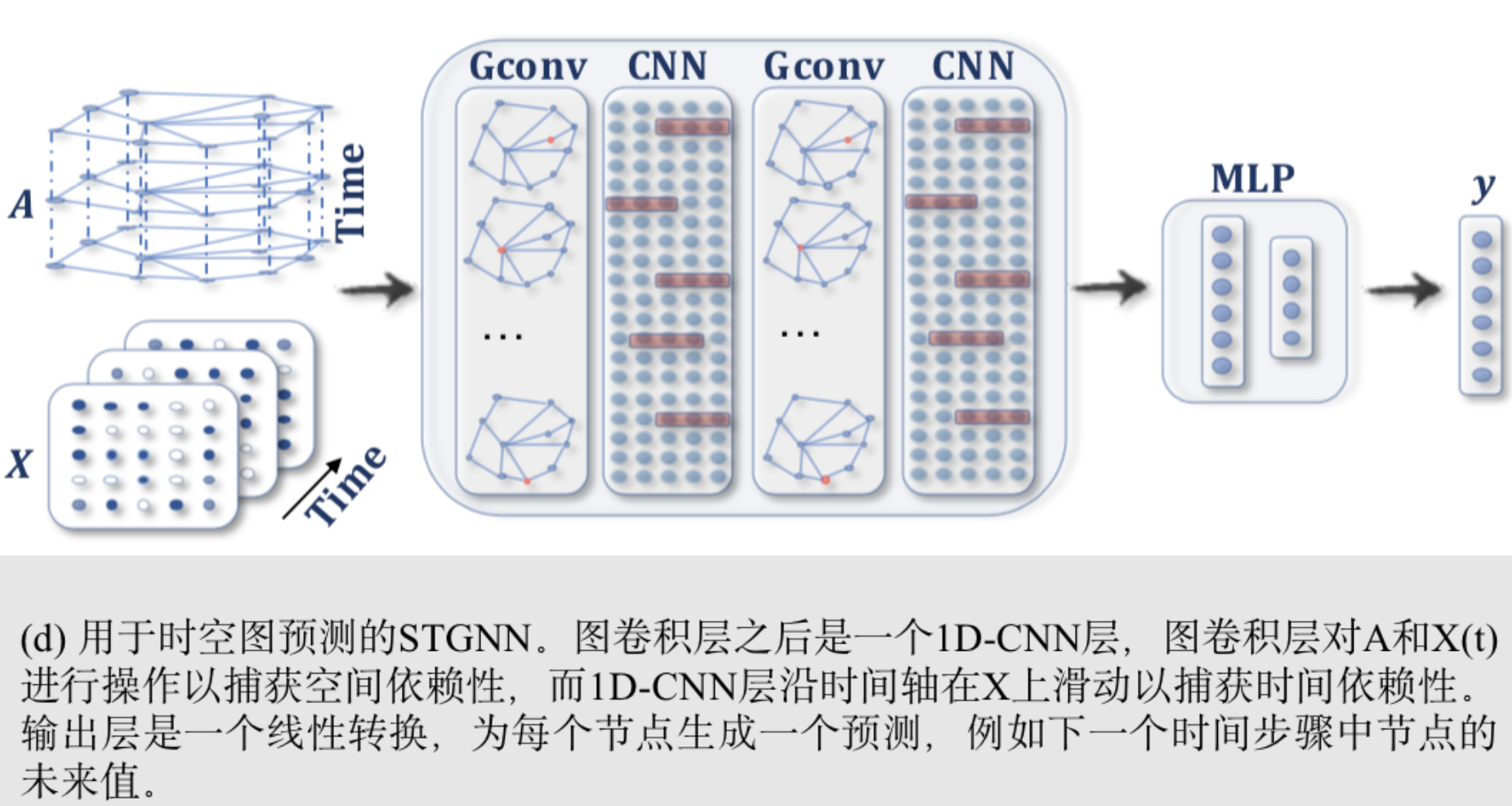
超微半导体公司(英語:Advanced Micro Devices, Inc.;縮寫:AMD、超微,或譯「超威」),創立於1969年,是一家專注於微处理器及相關技術設計的跨国公司,总部位于美國加州舊金山灣區矽谷內的森尼韦尔市。
 由 AMD 于 2019 年年中设计和推出。 是基于 Zen 2 微架构的多芯片处理器
由 AMD 于 2019 年年中设计和推出。 是基于 Zen 2 微架构的多芯片处理器
> cat lscpu.txt
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 1
Core(s) per socket: 32
Socket(s): 2
NUMA node(s): 2
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7452 32-Core Processor
Stepping: 0
CPU MHz: 2345.724
BogoMIPS: 4691.44
Virtualization: AMD-V
L1d cache: 32K
L1i cache: 32K
L2 cache: 512K
L3 cache: 16384K
NUMA node0 CPU(s): 0-31
NUMA node1 CPU(s): 32-63
Flags:
(Intel) fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht
(AMD) syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm
constant_tsc art rep_good nopl nonstop_tsc extd_apicid aperfmperf eagerfpu
(intel) pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand
(AMD) lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_l2
cpb cat_l3 cdp_l3 hw_pstate sme retpoline_amd
ssbd ibrs ibpb stibp
vmmcall
(intel) fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni
xsaveopt xsavec xgetbv1
(intel) cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local
(AMD) clzero irperf xsaveerptr
arat
(AMD) npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif
(intel) umip
(AMD) overflow_recov succor smca
- CPU(s):64 = the number of logical cores = “Thread(s) per core” × “Core(s) per socket” × “Socket(s)” = 1 * 32 * 2
- One socket is one physical CPU package (which occupies one socket on the motherboard);
- each socket hosts a number of physical cores, and each core can run one or more threads.
- In this case, you have two sockets, each containing a 32-core AMD EPYC 7452 CPU, and since that not supports hyper-threading, each core just run a thread.
fpu:板载 FPU(浮点支持)
vme:虚拟 8086 模式增强功能
de: 调试扩展 (CR4.DE)
pse:页表大小扩展(4MB 内存页表)
tsc:时间戳计数器(RDTSC)
msr:特定模型的寄存器(RDMSR、WRMSR)
pae:物理地址扩展(支持超过 4GB 的 RAM)
mce:机器检查异常
cx8:CMPXCHG8 指令(64 位比较和交换)
apic:板载 APIC(Advanced Programmable Interrupt Controller)
sep:SYS ENTER/SYS EXIT
mtrr:内存类型范围寄存器
pge:页表全局启用(PDE 和 PTE 中的全局位)
mca:机器检查架构
cmov:CMOV 指令(条件移动)(也称为 FCMOV)
pat:页表属性表
pse36:36 位 PSE(大页表)
pn:处理器序列号
clflush:缓存行刷新指令
mmx:多媒体扩展
fxsr: FXSAVE/FXRSTOR, CR4.OSFXSR # enables Streaming SIMD Extensions (SSE) instructions and fast FPU save & restore.
sse:英特尔 SSE 矢量指令
sse2:sse2
ht:超线程和/或多核
ss:CPU自监听
tm:自动时钟控制(Thermal Monitor)
ia64:英特尔安腾架构 64 位(不要与英特尔的 64 位 x86 架构混淆,标志为 x86-64 或由标志 lm 指示的“AMD64”位)
pbe:Pending Break Enable(PBE# 引脚)唤醒支持
syscall: SYSCALL (Fast System Call) and SYSRET (Return From Fast System Call)
nx:执行禁用 # NX 位(不执行)是 CPU 中使用的一项技术,用于分隔内存区域,以供处理器指令(代码)存储或数据存储使用
mmxext: AMD MMX extensions
fxsr_opt: FXSAVE/FXRSTOR optimizations
pdpe1gb: One GB pages (allows hugepagesz=1G)
rdtscp: Read Time-Stamp Counter and Processor ID
lm: Long Mode (x86-64: amd64, also known as Intel 64, i.e. 64-bit capable)
mp: Multiprocessing Capable.
3dnowext: AMD 3DNow! extensions
3dnow: 3DNow! (AMD vector instructions, competing with Intel's SSE1)
constant_tsc:TSC(Time Stamp Counter) 以恒定速率滴答
art: Always-Running Timer
rep_good:rep 微码运行良好
nopl: The NOPL (0F 1F) instructions # NOPL is long-sized bytes "do nothing" operation
nonstop_tsc: TSC does not stop in C states
extd_apicid: has extended APICID (8 bits) (Advanced Programmable Interrupt Controller)
aperfmperf: APERFMPERF # On x86 hardware, APERF and MPERF are MSR registers that can provide feedback on current CPU frequency.
eagerfpu: Non lazy FPU restore
pni: SSE-3 (“2004年,新内核Prescott New Instructions”)
pclmulqdq: 执行四字指令的无进位乘法 - GCM 的加速器)
monitor: Monitor/Mwait support (Intel SSE3 supplements)
ssse3:补充 SSE-3
fma:融合乘加
cx16: CMPXCHG16B # double-width compare-and-swap (DWCAS) implemented by instructions such as x86 CMPXCHG16B
sse4_1:SSE-4.1
sse4_2:SSE-4.2
x2apic: x2APIC
movbe:交换字节指令后移动数据
popcnt:返回设置为1指令的位数的计数(汉明权,即位计数)
aes/aes-ni:高级加密标准(新指令)
xsave:保存处理器扩展状态:还提供 XGETBY、XRSTOR、XSETBY
avx:高级矢量扩展
f16c:16 位 fp 转换 (CVT16)
rdrand:从硬件随机数生成器指令中读取随机数
lahf_lm:在长模式下从标志 (LAHF) 加载 AH 并将 AH 存储到标志 (SAHF)
cmp_legacy:如果是,超线程无效
svm:“安全虚拟机”:AMD-V
extapic:扩展的 APIC 空间
cr8_legacy:32 位模式下的 CR8
abm:高级位操作
sse4a:SSE-4A
misalignsse:指示当一些旧的 SSE 指令对未对齐的数据进行操作时是否产生一般保护异常 (#GP)。还取决于 CR0 和对齐检查位
3dnowprefetch:3DNow预取指令
osvw:表示 OS Visible Workaround,它允许 OS 绕过处理器勘误表。
ibs:基于指令的采样
xop:扩展的 AVX 指令
skinit:SKINIT/STGI 指令 # x86虚拟化的系列指令
wdt:看门狗定时器
tce:翻译缓存扩展
topoext:拓扑扩展 CPUID 叶
perfctr_core:核心性能计数器扩展
perfctr_nb:NB 性能计数器扩展
bpext:数据断点扩展
perfctr_l2:L2 性能计数器扩展
cpb:AMD 核心性能提升
cat_l3:缓存分配技术L3
cdp_l3:代码和数据优先级 L3
hw_pstate:AMD HW-PSstate Hardware P-state
sme:AMD 安全内存加密
retpoline_amd:AMD Retpoline 缓解 # 防止被攻击的安全策略
vmmcall:比 VMCALL 更喜欢 VMMCALL
fsgsbase:{RD/WR}{FS/GS}BASE 指令
bmi1:第一 组位操作扩展
avx2: AVX2 instructions
smep:主管模式执行保护
bmi2:第二 组位操作扩展
cqm:缓存 QoS 监控(Quality of Service )
rdt_a:资源总监技术分配
rdseed:RDSEED 指令,RDRAND 用于仅需要高质量随机数的应用程序
adx:ADCX 和 ADOX 指令
smap:超级用户模式访问保护
clflushopt:CLFLUSHOPT 指令, Optimized CLFLUSH,优化的缓存行刷回, 能够把指定缓存行(Cache Line)从所有级缓存中淘汰,若该缓存行中的数据被修改过,则将该数据写入主存;支持现状:目前主流处理器均支持该指令。
clwb: CLWB instruction (Cache Line Write Back,缓存行写回)作用与 CLFLUSHOPT 相似,但在将缓存行中的数据写回之后,该缓存行仍将呈现为未被修改过的状态;支持现状
sha_ni: SHA1/SHA256 Instruction Extensions
xsaveopt: Optimized XSAVE
xsavec: XSAVEC 使用压缩保存处理器扩展状态
xgetbv1: XGETBV with ECX = 1
cqm_llc: LLC QoS # last level cache (LLC)
cqm_occup_llc: LLC occupancy monitoring # Memory Bandwidth Monitoring (MBM)
cqm_mbm_total: LLC total MBM monitoring
cqm_mbm_local: LLC local MBM monitoring
clzero:CLZERO 指令,随 Zen 微体系结构引入的 AMD 供应商特定 x86 指令。CLZERO 通过向行中的每个字节写入零来清除由 RAX 寄存器中的逻辑地址指定的缓存行。
irperf:指令退休性能计数器
xsaveerptr:始终保存/恢复 FP 错误指针
arat: Always Running APIC Timer
npt:AMD 嵌套页表支持
lbrv:AMD LBR 虚拟化支持
svm_lock:AMD SVM 锁定 MSR
nrip_save:AMD SVM next_rip 保存
tsc_scale:AMD TSC 缩放支持
vmcb_clean:AMD VMCB 清洁位支持
flushbyasid:AMD 逐个 ASID 支持
解码辅助:AMD 解码辅助支持
pausefilter: AMD 过滤暂停拦截
pfthreshold:AMD 暂停过滤器阈值
avic:虚拟中断控制器
vmsave_vmload:虚拟 VMSAVE VMLOAD
vgif:虚拟 GIF
overflow_recov:MCA 溢出恢复支持 # Machine Check Architecture (MCA)
succor:不可纠正的错误控制和恢复
smca:可扩展的 MCA
ssbd ibrs ibpb stibp
英特尔处理器支持多种技术来优化功耗。 在本文中,我们概述了 p 状态(运行期间电压和 CPU 频率的优化)和 c 状态(如果内核不必执行任何指令,则优化功耗)。
ADCX
将两个无符号整数加上进位,从进位标志中读取进位,并在必要时将其设置在那里。 不影响进位以外的其他标志。
ADOX
将两个无符号整数加上进位,从溢出标志中读取进位,并在必要时将其设置在那里。 不影响溢出以外的其他标志。
暂无
暂无
https://unix.stackexchange.com/questions/43539/what-do-the-flags-in-proc-cpuinfo-mean