Train Stages: Pretrain, Mid-Train(CT), SFT, RL
导言
模型训练,为什么需要这么多阶段,每个阶段的独特职责和意义是什么。
导言
模型训练,为什么需要这么多阶段,每个阶段的独特职责和意义是什么。
导言
导言
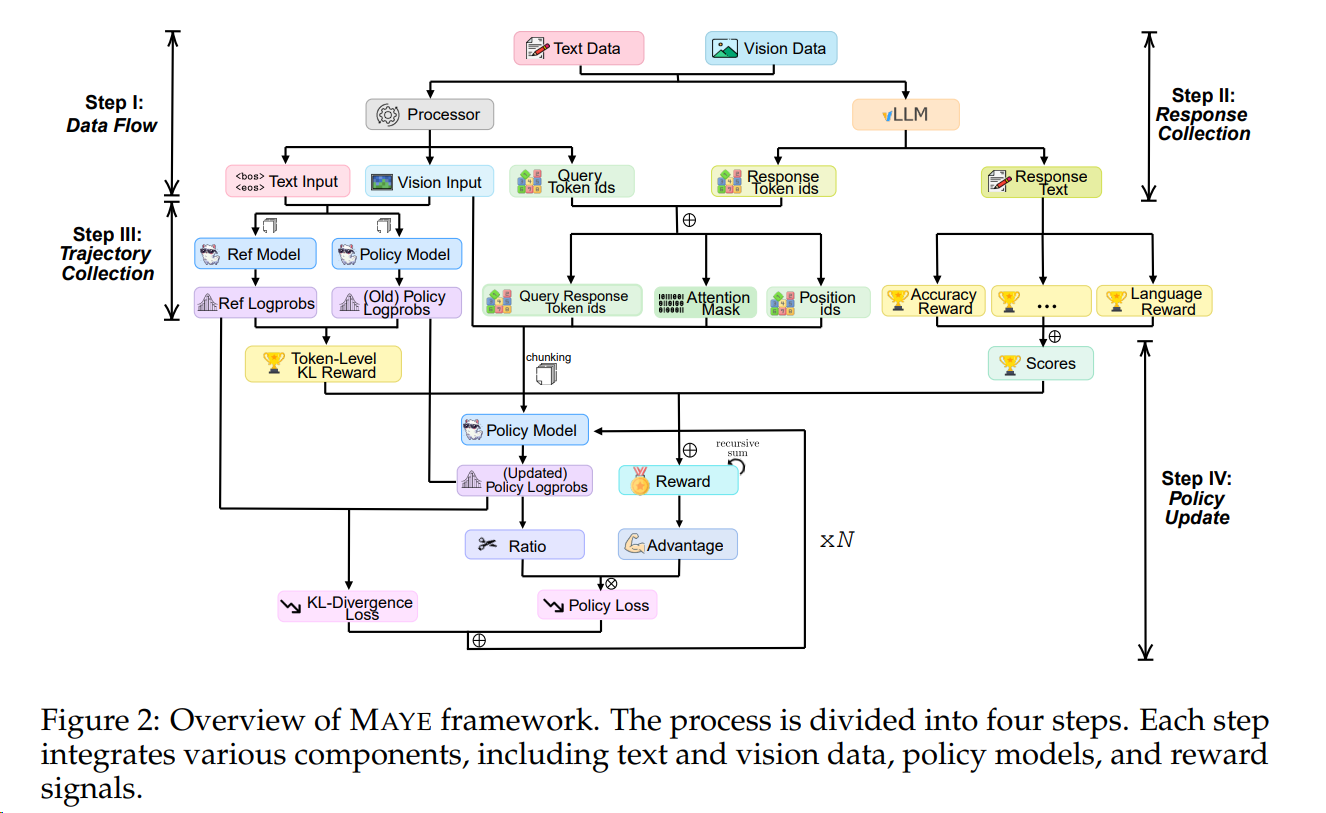
快速调研多模态强化学习及其ai infra(verl类似)的下一步方向、技术点和与LLM RL的差异点:
导言
导言
为什么之前认为金融只是调配资源,并不产生生产价值的我。也会想搞量化。
导言
第一次相亲(第二次见面)
导言
第一次相亲
导言
相亲是展现真实自我,寻找志趣相投另一半的过程。
导言
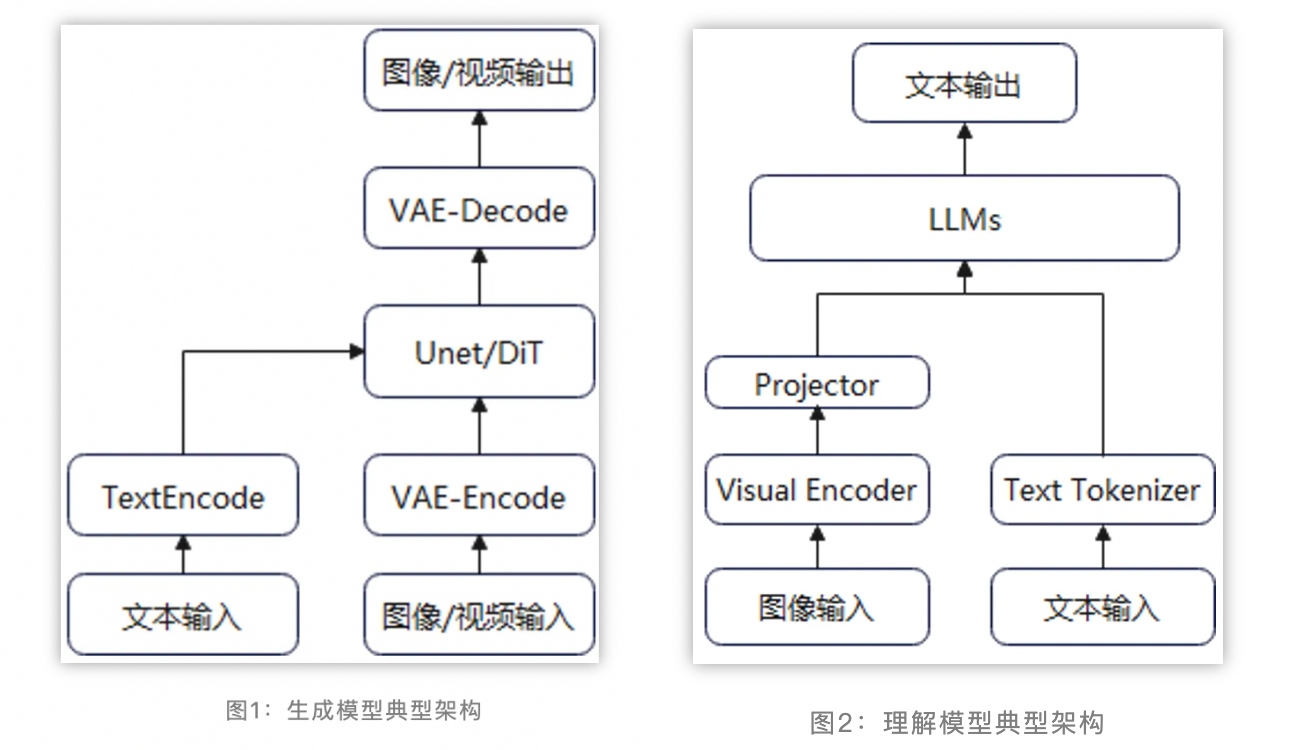
当前主流的多模态理解模型一般采用视觉编码器 + 模态对齐 + LLM的算法流程,充分复用已有视觉编码器的理解能力和LLM的基础能力。训练过程一般分为多个阶段,如先进行模态对齐的一阶段预训练,然后进行二阶段的参数微调。
排行榜: