VeRL Async
导言
异步 RL 的核心不是简单“并行化 PPO”,而是把 rollout、reward / logprob、训练更新和参数同步之间的同步屏障拆成可控队列与版本语义。它用 bounded staleness 换取更高 E2E throughput,但必须同时回答 old logprob 一致性、policy lag、partial rollout、样本丢弃和复现实验的问题。
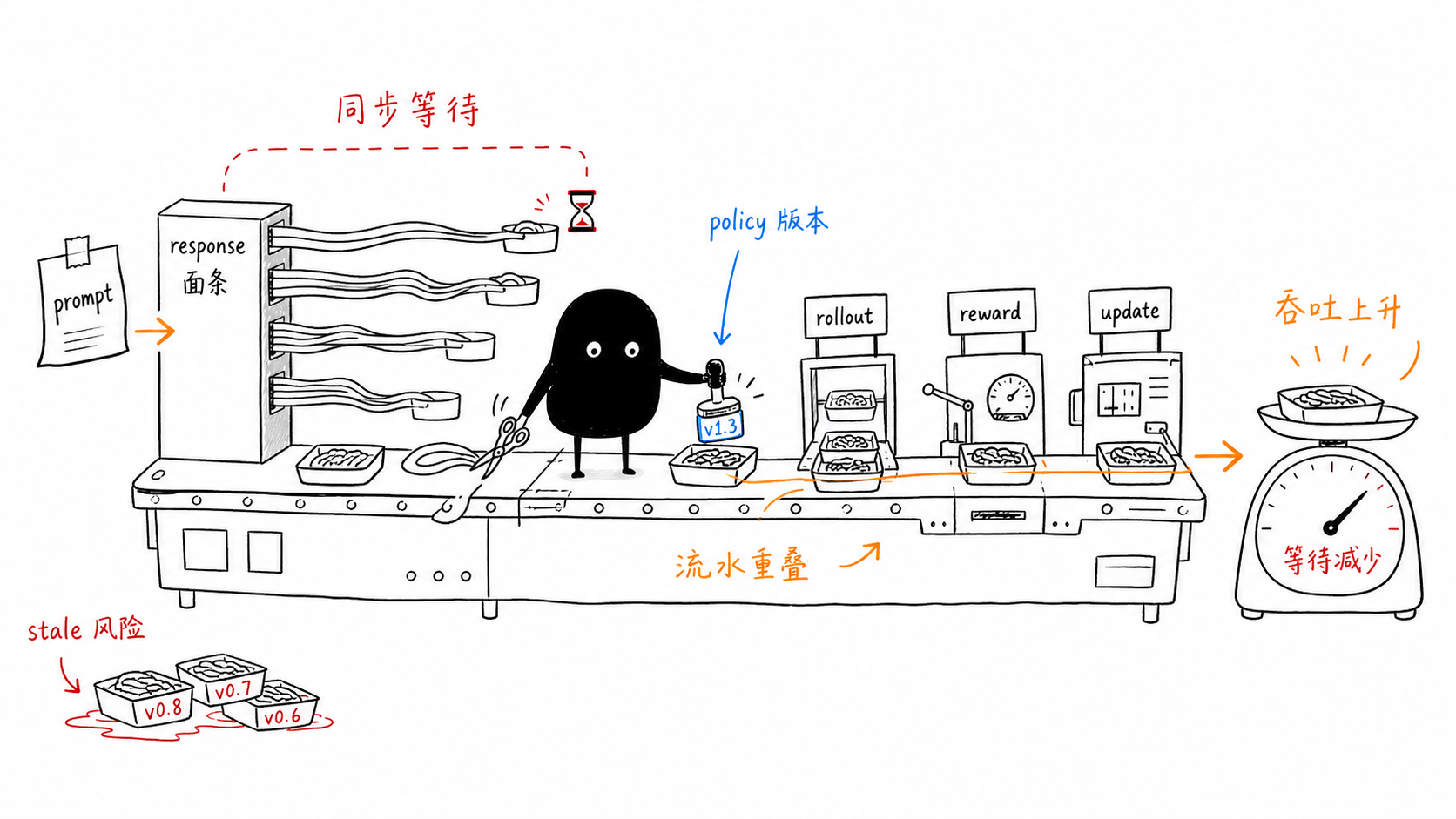
同步瓶颈¶
同步 PPO / GRPO 流程通常像这样:
这个流程语义清楚,debug 简单,但会产生明显 stage bubble:
- rollout 长尾样本拖住训练。
- reward 服务慢时训练卡等待。
- actor update 时 rollout 资源空闲。
- 权重同步前后有全局屏障。
异步训练试图把这些等待变成队列和版本控制问题:rollout 继续生产,trainer 持续消费,参数按规则同步,而不是每个 step 都全局对齐。
异步不是免费午餐
异步减少等待,但会引入 policy lag。只看 wall-clock speedup 而不记录 stale sample ratio、policy version gap 和 old logprob 来源,无法判断收益是否可靠。
FullAsync 架构¶
verl 的 Fully Async Policy Trainer 把系统拆成四个角色:1
| 组件 | 职责 |
|---|---|
| Rollouter | 逐样本生成 rollout,并写入 MessageQueue |
| MessageQueue | 缓冲 rollout 样本,隔离生产与消费速度 |
| Trainer | 按 batch 消费样本并做本地 update |
| ParameterSynchronizer | 将 Trainer 参数同步给 Rollouter |
官方文档报告,在 128 GPUs 上训练 Qwen2.5-7B 时,FullAsync 相比同步 baseline 取得 2.35x 到 2.67x 性能提升,且未显著影响结果。1
核心参数¶
FullAsync 的关键不是一个布尔开关,而是一组 freshness 控制:
| 参数 | 含义 | 风险 |
|---|---|---|
async_training.require_batches |
Trainer 一次取多少个 ppo_mini_batch_size 后训练 |
太小可能分布不稳,太大又增加等待 |
async_training.trigger_parameter_sync_step |
做多少次本地 update 后同步 Rollouter | 过大时 policy lag 增大 |
async_training.staleness_threshold |
允许使用多少比例 stale samples | 过大时 KL 和 response length 易抖 |
async_training.partial_rollout |
参数同步时是否打断并恢复未完成 rollout | 需要准确记录 partial span |
actor_rollout_ref.actor.use_rollout_log_probs |
是否使用 rollout 生成的 old logprob | 关系到 PPO/GRPO ratio 语义 |
官方文档里 staleness_threshold=0 表示严格同步;当 rollouter 足够快时,staleness_threshold=1 接近 one-step off-policy,但文档建议小于 1。1
四种模式¶
on-policy pipeline¶
语义最清楚,Rollouter 生成一个训练批次后 Trainer 训练,然后同步参数。长尾等待仍然明显。
stream off-policy pipeline¶
Rollouter 一次生产多个 mini-batch,Trainer 多次本地 update 后再同步。它减少了局部空泡,但仍不允许 stale samples。
async stream with stale samples¶
同步后仍允许消费一部分旧参数生成的样本。收益来自更少等待,风险来自 off-policy 偏差。
async stream with partial rollout¶
参数同步时可以打断仍在生成的样本,同步后继续生成。它进一步减少等待慢样本的 idle time,但要求日志记录 partial rollout ratio 和 max partial span。
横向比较¶
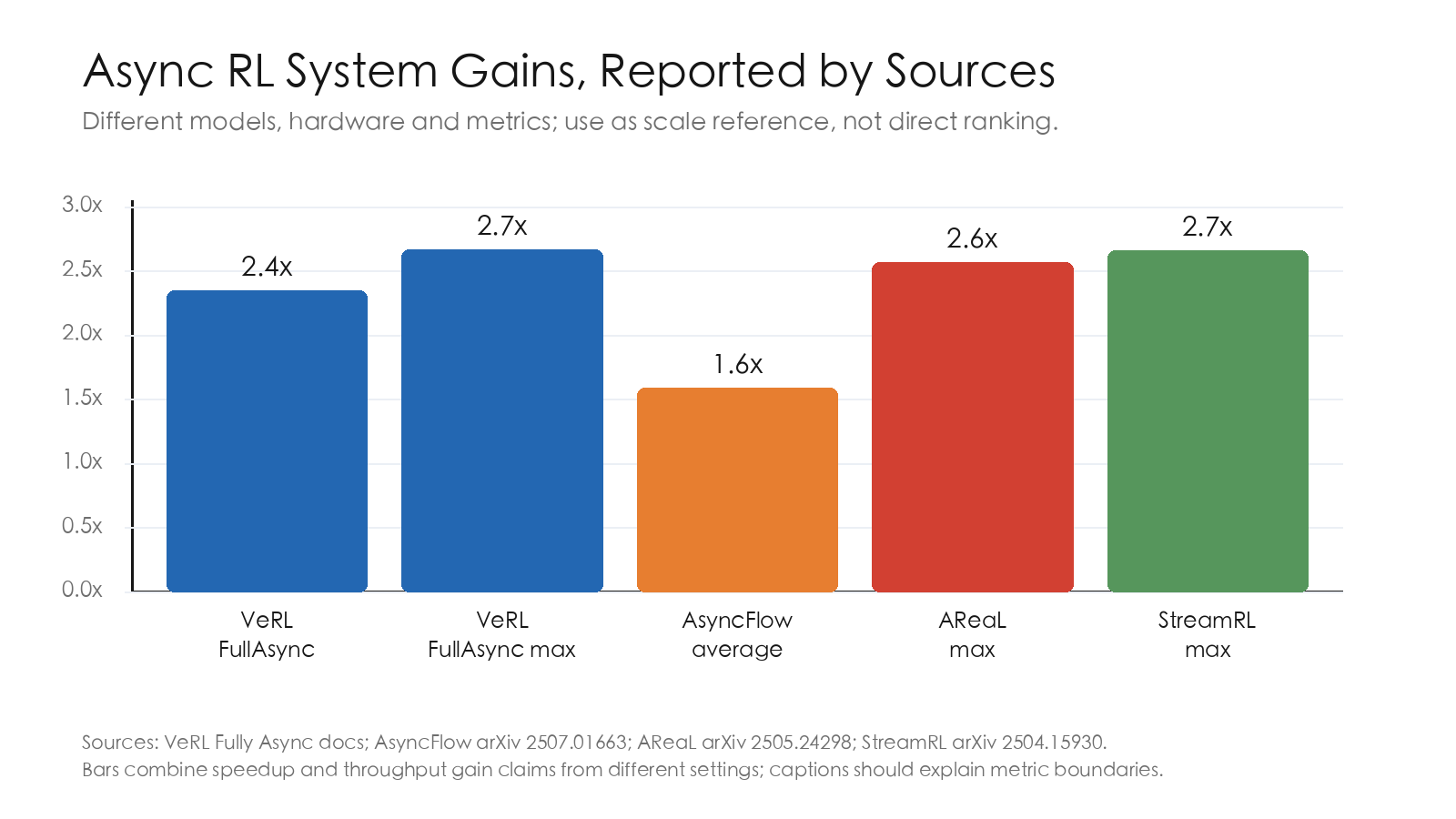
AsyncFlow 把异步 RL 的数据系统能力进一步抽象出来,中心是面向 RL 多任务流的 TransferQueue:producer / consumer 只读写自己关心的字段,控制器维护 metadata,训练侧可以像 DataLoader 一样消费 ready samples。论文报告平均 1.59x throughput improvement。2
AReaL 关注 generation 与 training fully decoupled,并提出 staleness-aware training / decoupled PPO。论文报告最高约 2.57x 训练加速。3
StreamRL 关注 disaggregated stream generation,让 completed samples 以 stream 方式进入训练,并结合 length-aware / skew-aware 调度。论文报告最高 2.66x throughput 和最高 1.33x cost-effectiveness。4
这些工作共同说明:异步收益主要来自减少 stage idle,而不是提高单个 kernel 的算力效率。
正确性风险¶
异步训练必须把样本和版本绑定起来:
- old logprob:必须对应生成该 response 的行为策略。
- policy version gap:每条样本应记录 rollout policy 和 update policy 的差距。
- stale sample ratio:要统计实际被训练消费的 stale 样本比例。
- partial rollout:要记录同一 trajectory 是否跨越多个 policy version。
- drop / retry:队列满、reward 失败或 rollout timeout 时不能静默改变数据分布。
old logprob 是语义锚点
在异步设置里,old logprob 最好随 rollout 一起生成或显式记录来源。否则 Trainer 后算 old logprob 时很容易误用当前参数,把 off-policy 样本伪装成 on-policy 样本。
验证指标¶
| 层次 | 指标 | 目的 |
|---|---|---|
| 系统 | samples/s、tokens/s、step/hour、stage idle ratio | 判断是否真的减少等待 |
| 队列 | queue depth、drop count、message latency | 判断 backpressure 是否健康 |
| 同步 | parameter sync latency、sync interval | 判断参数同步是否成为新瓶颈 |
| 算法 | policy version gap、stale sample ratio、KL、clipfrac、entropy | 判断 off-policy 影响是否可控 |
| 结果 | reward / accuracy wall-clock 曲线 | 判断是否更快达到目标分数 |
实践顺序¶
- 同步 baseline:记录每个 stage 的耗时和 idle ratio。
- stream off-policy:先保持
staleness_threshold=0,只减少局部空泡。 - 小 staleness:逐步提高 threshold,通常先小于 1。
- partial rollout:只在长尾明显且 metadata 完整时开启。
- 组合 TransferQueue:当数据搬运和 controller 成为瓶颈时,再引入数据系统层解耦。
总结¶
FullAsync、AsyncFlow、AReaL 和 StreamRL 的共同目标是减少 RL 后训练的端到端等待。但异步不是越多越好,真正要控制的是 bounded staleness:样本可以旧一点,但旧到什么程度、来自哪个 policy、old logprob 怎么算、训练曲线是否稳定,都必须可观测。
参考文献¶
-
Zhenyu Han et al., AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training, arXiv, 2025. ↩
-
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning, arXiv, 2025. ↩
-
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation, arXiv, 2025. ↩