VeRL Feature Survey
导言
这篇文章现在作为 verl / RL infra 特性地图:把 vLLM 图模式、speculative decoding、router replay、FullAsync / AsyncFlow 和 TransferQueue 放到同一张系统图里,但不再承载所有细节。
核心结论仍然是:这些特性不在同一层。 有的减少推理执行开销,有的解决 decode 串行性,有的保证 MoE 路由一致性,有的把 rollout 与训练重叠,有的把数据从 single controller 中解耦。真正的收益来自先定位瓶颈,再打开对应特性。
四个时钟¶
RL 后训练系统可以拆成四个时钟:
- 推理时钟:vLLM / SGLang 负责把 prompt 变成 response,核心瓶颈常见于 decode 串行性、KV cache、batch shape 与 kernel launch。
- 策略时钟:actor 参数不断更新,rollout、old logprob、new logprob 和 ref logprob 必须知道自己使用的是哪个 policy version。
- 数据时钟:样本字段不是一次性出现,
prompt、response、reward、old_log_prob、ref_log_prob、advantages有不同生产者和消费者。 - 一致性时钟:MoE 路由、训练后端与推理后端的数值差异,会让“同一条样本”的概率比较混入框架差异。
先分层再开关
FULL_DECODE_ONLY、router replay、FullAsync 和 TransferQueue 都可能提升端到端效率,但它们解决的问题不同。把它们都叫“加速开关”会误导实验设计。
文章地图¶
| 专题 | 文章 | 解决的问题 | 主要风险 |
|---|---|---|---|
| vLLM 图模式 | VeRL Rollout Inference | enforce_eager、cudagraph_mode、cudagraph_capture_sizes 如何影响 rollout 推理 |
图显存、capture warmup、版本参数差异 |
| speculative decoding | VeRL Speculative Decoding | MTP、EAGLE、DFlash 如何缩短 decode | logprob 口径、draft stale、metadata 丢失 |
| MoE 路由一致性 | VeRL Router Replay | R2/R3 如何拉齐 rollout、old logprob、actor update 的 expert 路径 | routed experts 回传、后端支持、KL 解释 |
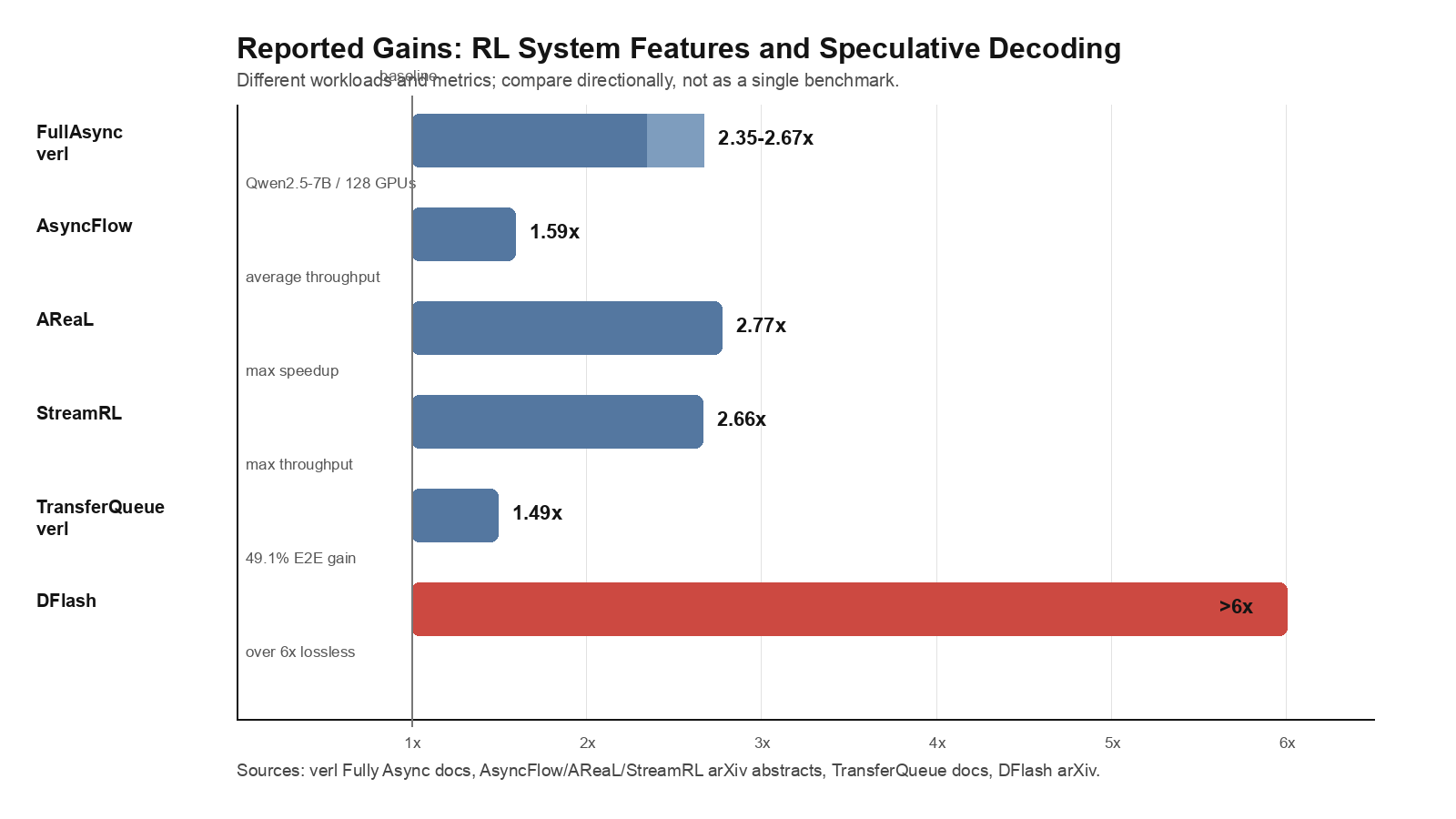
| 异步流水 | VeRL Async | FullAsync、AsyncFlow、AReaL、StreamRL 如何减少 stage bubble | policy lag、stale samples、partial rollout |
| 数据系统 | VeRL TransferQueue | TransferQueue 如何拆开 control flow 与 data flow | 采样分布、字段生命周期、恢复语义 |
开启顺序¶
推荐按风险从低到高推进:
- 同步 baseline:先跑通 eager / 小 batch / 短 response,确认 reward、mask、logprob、KL 和 checkpoint 语义。
- vLLM graph:设置
enforce_eager=False,优先使用FULL_AND_PIECEWISE;若是 P/D decode-heavy 或显存压力明显,再试FULL_DECODE_ONLY。 - capture sizes:基于真实 decode batch 分布选择尺寸,不要只照抄示例。
- MoE router replay:Dense 模型跳过;MoE 先 R2,确认稳定后再 R3。
- MTP / DFlash:先在纯 serving benchmark 看 acceptance、tokens/s、latency 和显存,再接入 RL rollout。不要只看 acceptance rate。
- FullAsync:先
staleness_threshold=0做 stream off-policy,再逐步提高 threshold,通常不建议一开始超过 1。 - TransferQueue:当 single controller、对象传输、host memory 或样本字段生命周期成为瓶颈时打开。小规模实验里先不用急。
验证指标¶
每个 feature 至少要回答三件事:它减少了什么等待,它引入了什么不一致风险,它是否改变最终训练曲线。
| 层次 | 指标 | 解释 |
|---|---|---|
| vLLM graph | decode tokens/s、p50/p99 latency、capture hit ratio、warmup time、peak memory | 判断图捕获是否覆盖主流 batch |
| speculative | acceptance length、tokens/s、draft overhead、verify overhead、output quality | 判断 MTP / DFlash 是否抵消额外成本 |
| router replay | routed expert diff、KL、clip ratio、old/new logprob delta | 判断 MoE 路由是否被拉齐 |
| async | trainer idle ratio、rollouter idle ratio、stale sample ratio、policy version gap | 判断流水是否减少空泡且 stale 可控 |
| TransferQueue | queue depth、field ready latency、KV put/get latency、single controller CPU time、host memory | 判断是否绕开 controller 和对象传输瓶颈 |
总结¶
这组特性的共同目标是提高 RL 后训练的有效吞吐,但它们的作用层次不同:
- vLLM CUDA Graph 解决单次推理执行开销。
- MTP / DFlash 解决 decode 串行性。
- router replay 解决 MoE 训推路径一致性。
- FullAsync / AsyncFlow 解决 rollout 与训练的 stage bubble。
- TransferQueue 解决数据依赖、single controller 和跨任务消费语义。
所以最实用的判断不是“哪个特性最强”,而是:当前瓶颈属于 kernel、decode、路由一致性、stage idle,还是数据流管理。 找准瓶颈后再开对应特性,收益才会稳定。