VeRL Router Replay
导言
Router Replay 的核心不是让 MoE 路由更快,而是把 rollout、old logprob 重算和 new logprob 更新三段路径的专家选择对齐。MoE 的 top-k routing 是离散分叉,微小数值差异会导致 expert 集合突变;一旦 old/new logprob 的差异混入“路由换了”而不是“策略变了”,PPO / GRPO 的 ratio、clip 和 KL 都会失真。
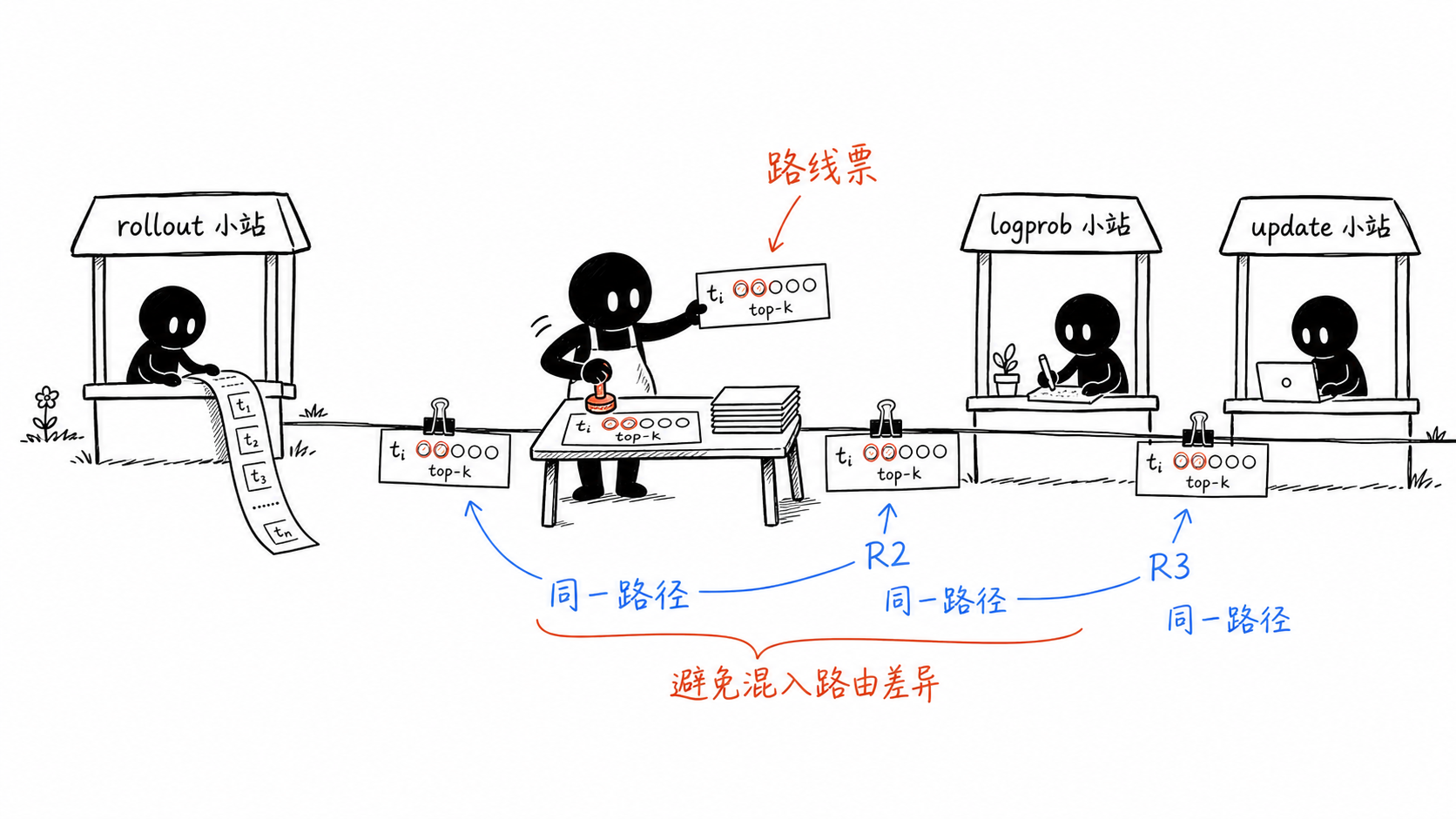
为什么需要 replay¶
Dense 模型中,同一个 token 的前向路径基本连续;MoE 模型中,只要 top-k expert 发生变化,后续计算就进入另一组 expert 网络。路由器会把很小的数值差异放大成离散路径差异。
在 PPO / GRPO 中,核心比率是:
这个 ratio 本来应该衡量策略更新前后的概率变化。但如果 old logprob 是在一组 expert 上算的,而 update 阶段 new logprob 又走了另一组 expert,那么 ratio 里同时包含两种变化:
- 策略参数变化:算法真正想优化的 policy improvement。
- 专家路径突变:由后端、数值、batch 或路由差异引入的系统噪声。
Router Replay 的目标就是把第二类噪声压下去,让 old/new logprob 的比较更接近“同一路由支撑集下的策略变化”。
Replay 不是冻结 router
Router replay 复放的是 top-k expert ids 或 mask。训练侧仍然可以在这些 expert 上用当前 router logits 计算 gating weight,因此梯度仍能流回 router。它锁定的是比较路径,不是禁止模型学习新的路由。
三种模式¶
verl 的 router replay 示例把模式限定为 disabled、R2 和 R3。配置路径随训练 engine 不同而变化:Megatron 使用 actor.megatron.router_replay.mode,VeOmni 使用 actor.veomni.router_replay.mode。1
| 模式 | 语义 | 记录位置 | 复放位置 | 配置重点 |
|---|---|---|---|---|
disabled |
不记录、不复放 | 无 | 无 | dense 模型或 baseline |
R2 |
训练侧 replay | actor compute_log_prob |
actor update | 只开 actor engine 的 router_replay.mode=R2 |
R3 |
rollout replay | rollout backend | old logprob 与 actor update | 同时打开 rollout 返回路由结果 |
R2 的典型配置是:
R3 的典型配置是:
actor_rollout_ref.actor.megatron.router_replay.mode=R3
actor_rollout_ref.rollout.enable_rollout_routing_replay=True
官方 trainer 代码里还有一个重要防护:R2 和 enable_rollout_routing_replay=True 不能同时打开。后者只用于 R3,否则 batch 中会同时出现两套 routed_experts 来源。2
R2 与 R3¶
R2:训练侧对齐¶
R2 在 actor compute_log_prob 阶段记录 top-k expert ids,并在 actor update 阶段复放。它解决的是 recompute old logprob 与 update new logprob 之间的路由漂移。
适合先用 R2 的场景:
- 先验证 actor 训练侧是否稳定。
- rollout 后端暂时不能返回 routed experts。
- 希望先把影响范围限制在训练 engine 内。
R3:全链路对齐¶
R3 在 rollout 阶段就记录 routed experts,并在 old logprob 重算和 actor update 中复放。因此它同时缓解两类差异:
- rollout 后端与训练后端之间的路由差异。
- old logprob 与 update 阶段之间的路由差异。
R3 更适合大 MoE、SGLang / vLLM rollout、Megatron / VeOmni 训练后端混合的场景,但它要求 rollout backend 支持返回 routing 结果。verl README 明确提到 R3 依赖 vLLM 与 SGLang 对 routed experts 返回能力的支持。1
数据字段¶
当前在线 RL 主路径更像“batch 字段传递”,而不是通过 record_file / replay_file 落盘。关键字段是 routed_experts:它随 batch 在 rollout、old logprob 和 actor update 之间传递。
写实验日志时建议至少记录:
router_replay.modeenable_rollout_routing_replayrouted_experts是否存在- rollout backend 与训练 engine 版本
- MoE expert parallel / expert load balancing 配置
- old/new logprob diff
- routed expert diff ratio
验证指标¶
Router Replay 不是一个只看 throughput 的 feature。它应该通过一致性与训练稳定性指标验证:
| 层次 | 指标 | 目的 |
|---|---|---|
| 路由 | routed expert diff ratio、top-k overlap | 判断路径是否被拉齐 |
| 概率 | old/new logprob delta、training-inference KL | 判断 ratio 是否混入后端差异 |
| PPO/GRPO | KL、clipfrac、entropy、grad norm | 判断优化信号是否稳定 |
| 训练曲线 | reward、response length、pass rate | 判断最终训练是否收益 |
不要只看 reward
Router Replay 的主要收益可能首先体现在 KL、clipfrac 和 logprob diff 上。如果只看短期 reward,容易把“训练暂时没崩”误认为一致性已经解决。
实践顺序¶
- dense baseline:先确认非 MoE 或关闭 router replay 的同步路径能跑通。
- MoE + disabled:记录 routed expert diff、KL 和 logprob 波动。
- 打开 R2:验证训练侧 recompute/update 路由是否对齐。
- 打开 R3:确认 rollout backend 返回
routed_experts,再拉齐完整链路。 - 和异步组合:异步训练下同时记录 policy version gap 和 routed expert diff。
总结¶
Router Replay 是 MoE RL 的一致性基础设施。R2 解决训练侧 replay,R3 解决 rollout 到 update 的全链路 replay。它的目标不是提高单次 forward 速度,而是让 PPO / GRPO 的 old/new logprob 比较真正反映策略变化,而不是 expert 路径变化。
参考文献¶
-
verl router replay README, Megatron example, and VeOmni example. ↩↩
-
verl
ray_trainer.pyincludes a guard against enablingR2and rollout routing replay simultaneously. ↩