Personal Advantage Workflow
导言
多局点、多任务、多角色同时推进时,真正稀缺的不是勤奋,而是 判断力、取舍能力和可复用记录。均匀响应所有任务只能保证不出明显纰漏,却很难形成个人优势;优势通常来自少数高风险、高杠杆、高不确定、强依赖的局点。
本文把工作链路整理成一个可执行系统:先识别重点风险局点,再拒绝低优先级任务;先快穿刺关键假设,再并行派活和紧跟踪;先用原理、显存、性能 MFU 和投产约束做建模,再用实践验证、详细记录和持续修正形成历史;最后把优势进展、后续风险和必要求助稳定汇报出去。
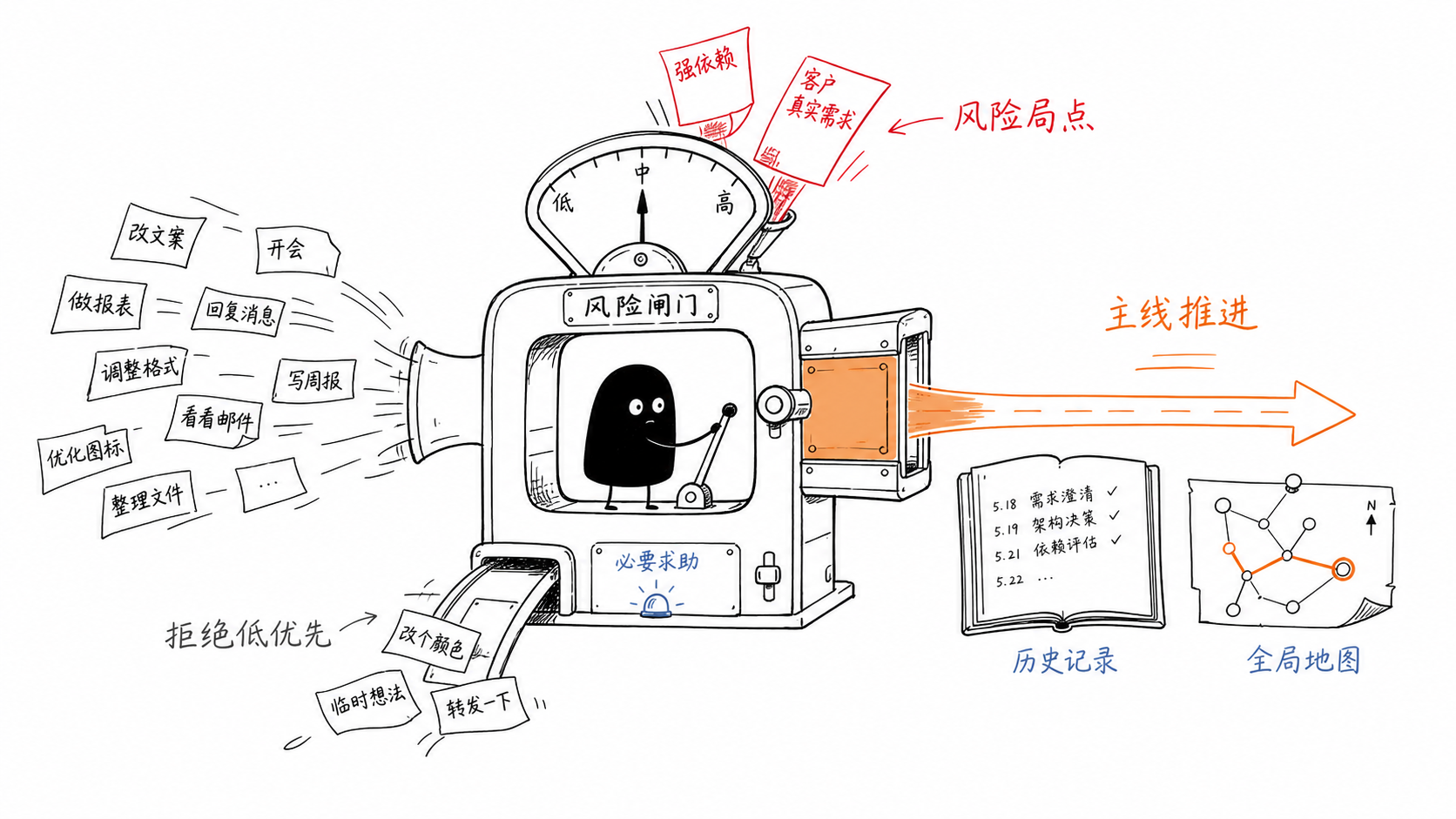
核心判断¶
这套方法的第一原则是:不要把所有任务当作同一种任务。在复杂工作里,任务至少分成四类:
- 重点风险局点:影响客户承诺、投产窗口、架构方向、人力依赖或技术可行性,一旦失控会改变全局。
- 优势构造局点:能体现个人不可替代性,例如深挖客户需求、判断技术路线、建模显存与性能、推动阻塞、形成报告。
- 均匀基线任务:必须合格完成,但很少成为优势来源,例如例行格式调整、重复汇总、低风险会议跟进。
- 低优先级噪声:没有明确客户、没有交付窗口、没有依赖解除价值、没有可验证结果的临时任务。
优势不是把第四类任务也做得很漂亮,而是 稳定识别第一类和第二类任务,并让第三类低成本合格完成。
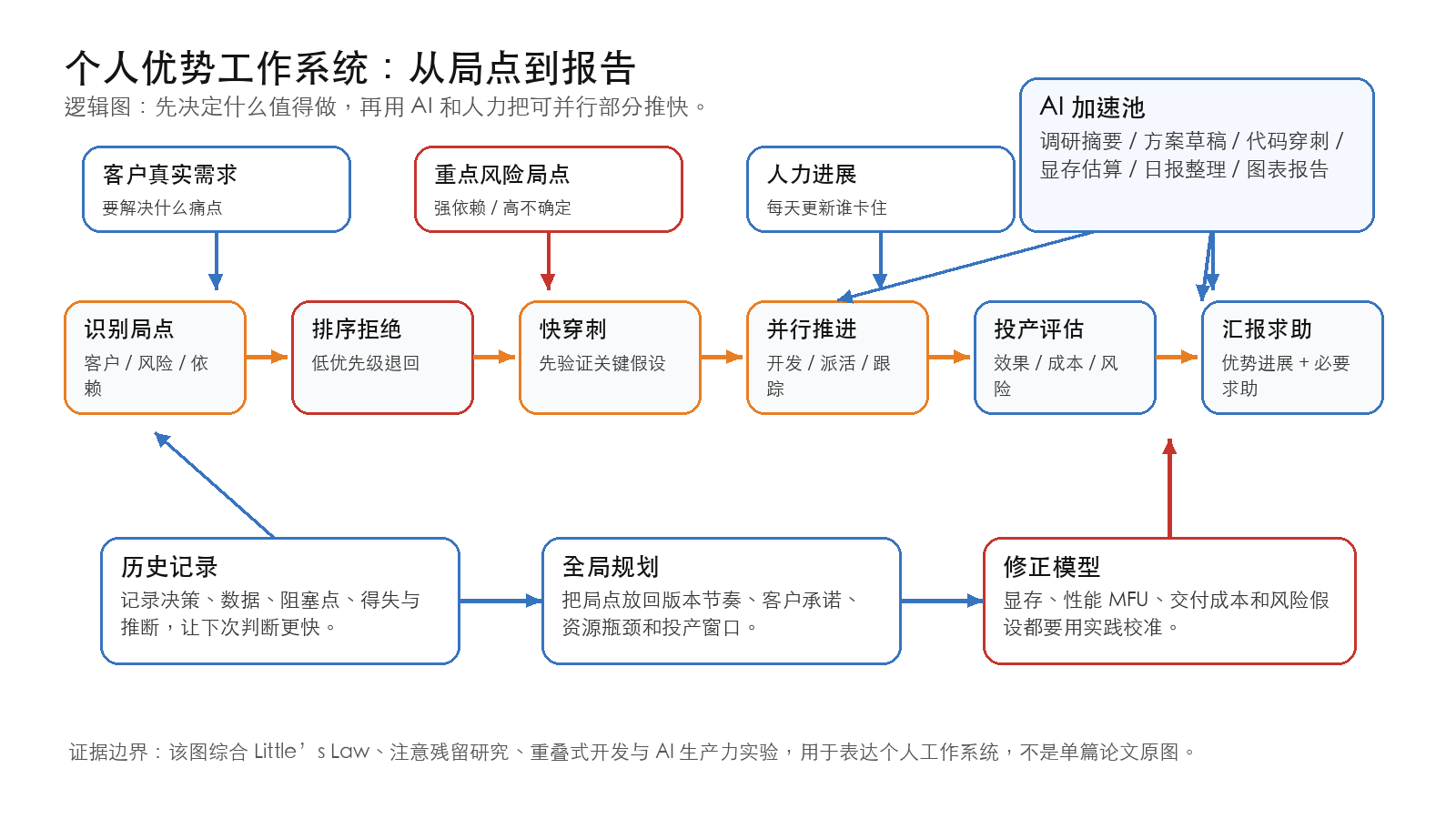
优先级系统¶
优先级不是把待办事项排成一列,而是回答三个问题:
- 如果今天不处理,哪件事会让全局变差?
- 如果今天处理,哪件事会释放后续人力或路径?
- 如果今天拒绝,哪件事其实不会带来真实损失?
Little's Law 给了一个很朴素的约束:在稳定系统里,队列中的工作量 L 约等于到达率 λ 乘以等待时间 W。1 换成个人工作,就是 并发越多,平均完成周期越长。所以“会拒绝低优先级任务”不是态度问题,而是吞吐和交付周期问题。
注意残留研究也指向同一个结论:从任务 A 切换到任务 B 后,人的一部分注意仍会留在 A 上,尤其当 A 尚未完成或存在压力时。2 因此低优先级任务的真实成本不只是它本身耗时,还包括它打断高价值任务后的恢复成本。
优先级闸门
每个新任务进入前,先问四个问题:是否有客户真实需求,是否解除强依赖,是否降低重大风险,是否产生可复用记录。四个都没有,就不进入主线;最多进入批处理池。
我会把任务粗分成四档:
- P0 风险局点:客户承诺、投产窗口、关键依赖、技术可行性或资源瓶颈正在变化。需要当天推动、当天记录、当天汇报风险。
- P1 优势局点:能形成判断、模型、报告、复用模板、客户理解或跨团队影响。需要安排深度时间和阶段性产出。
- P2 基线局点:必须完成但路径清楚。适合批处理、模板化、交给 AI 草拟或派给合适人力。
- R 拒绝/延后:没有明确收益、没有明确 owner、没有截止损失、没有复用价值。需要礼貌拒绝、延后或要求对方补齐背景。
快穿刺¶
“快开发/多派活/紧跟踪”的前提是先做 快穿刺。快穿刺不是把完整方案做完,而是用最小成本刺穿最关键的不确定性。
一个好的穿刺任务要有四个字段:
- 假设:我们相信什么,例如“当前瓶颈在显存峰值而不是算子吞吐”。
- 证据:用什么证明,例如 profiler、最小脚本、客户日志、显存估算表、对比实验。
- 退出条件:什么结果说明这条路不值得继续。
- 下游动作:穿刺成功后谁接、失败后转向哪里。
穿刺模板
快穿刺的价值在于 早知道得失。一个半天内证明不可行的穿刺,比一个两周后才发现方向错的完整开发更有价值。
原理与建模¶
多局点工作中,能构造个人优势的技术点通常不是“知道一个名词”,而是能把问题落到 原理、模型、指标和可投产约束 上。
对 AI Infra 和训练系统类问题,至少要能快速回答:
- 显存模型:参数、梯度、优化器状态、activation、KV cache、通信 buffer 和碎片分别在哪里增长。
- 性能模型:理论 FLOPs、实际吞吐、通信时间、数据加载、同步等待和 pipeline bubble 分别占多少。
- MFU 估算:Model FLOPs Utilization 不是一个装饰指标,而是把模型理论计算量、设备峰值和实际步时联系起来的利用率口径。PaLM 论文中使用 MFU 来衡量大规模训练的有效利用率,适合作为训练系统性能讨论的共同语言。4
- 投产约束:是否稳定、是否可复现、是否能监控、是否有回滚、是否有 owner、是否符合客户真实需求。
不要只报效果
只报“性能提升了”是不够的。更有价值的汇报是:提升来自哪里,代价是什么,在哪些配置上成立,哪些场景可能失效,投产前还缺什么证据。
因此技术判断最好写成“模型 + 实测 + 边界”:
判断:当前方案适合优先做 rollout 并行和同步节奏优化。
模型:显存峰值可控,瓶颈更可能来自 sync_weight 和等待。
实测:最小配置下 sync 约占 wall time 的主要部分。
边界:大模型、长序列、多节点下通信拓扑可能改变结论。
动作:先做两组穿刺,再决定是否进入完整开发。
并行与 AI¶
并行不是把所有事情同时开工,而是把不同不确定性拆开,让它们 在互不阻塞的边界内同时收敛。Takeuchi 和 Nonaka 对新产品开发的经典讨论强调了重叠阶段和跨职能协作的重要性:团队不一定要等上游完全结束,关键是保持共同目标、快速反馈和相互校准。3
AI 的位置也是这样:它适合加速那些边界清晰、可验收、可回滚、可记录的子任务,而不适合替代优先级判断。
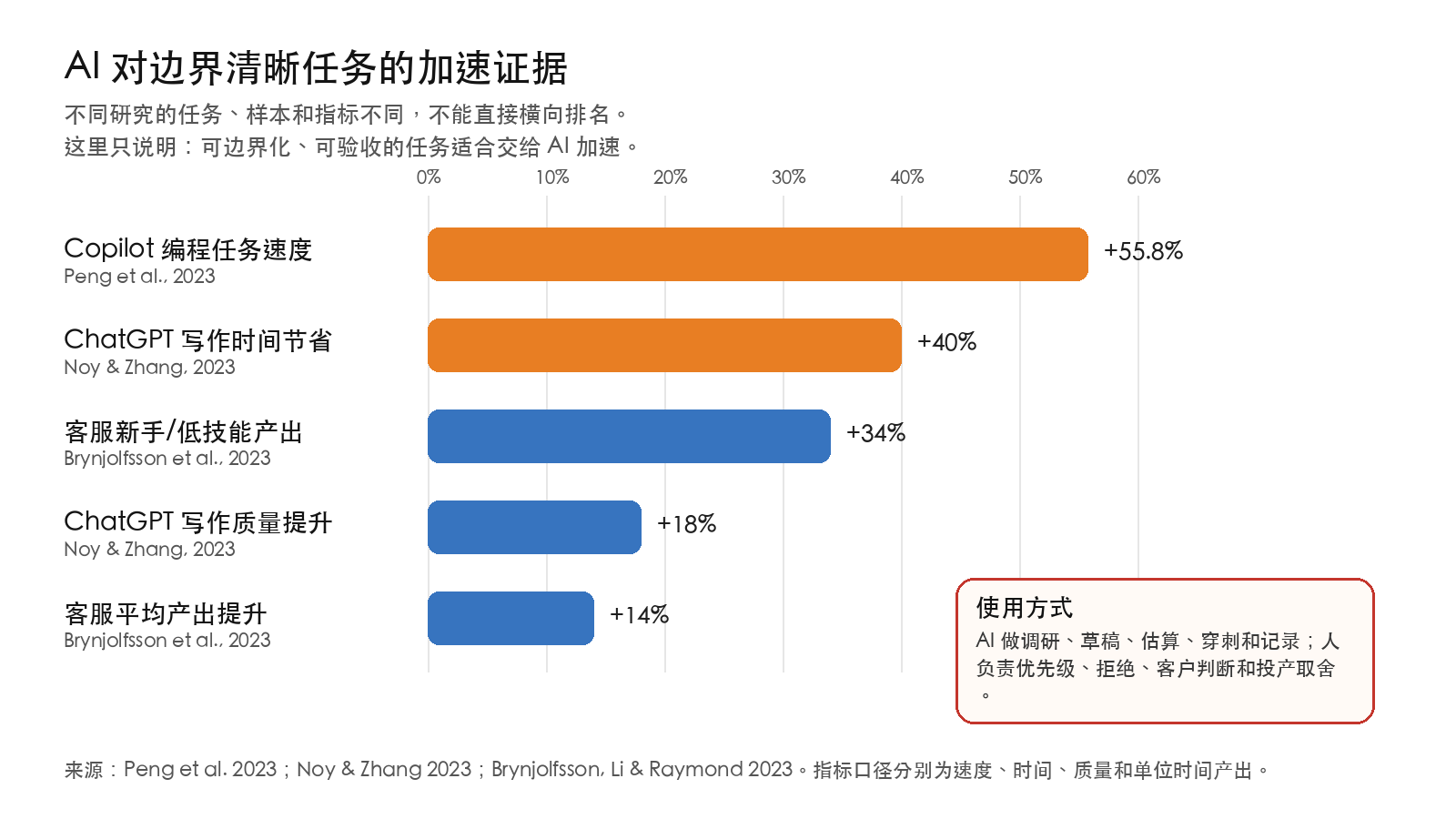
这些研究的共同启示不是“AI 可以替代人”,而是:当任务被清晰定义、结果可验收、反馈足够快时,AI 能显著减少局部执行成本。Copilot 受控实验报告开发者完成指定编程任务快了 55.8%。5 Noy 和 Zhang 的写作实验报告时间减少约 40%、质量提升约 18%。6 Brynjolfsson、Li 和 Raymond 的客服现场研究报告平均生产率提升约 14%,新手和低技能员工收益更大。7 2026 年的 AI 编程任务元分析也提醒:总体效果为正,但模型、任务、人员和验收方式会造成明显差异。8
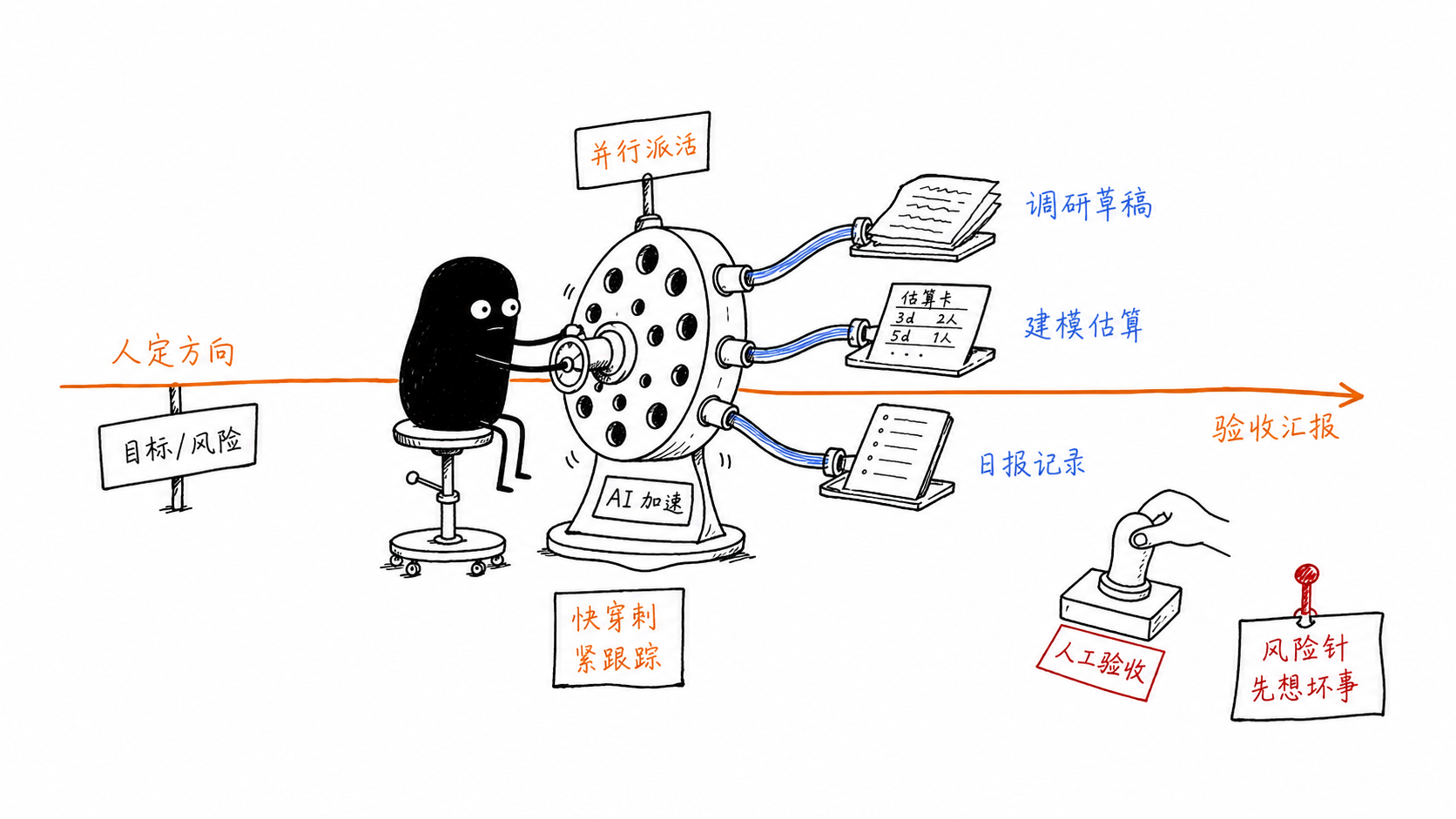
我会把工作拆成下面几类:
| 工作单元 | 是否能并行 | 是否适合 AI | 人必须负责的部分 |
|---|---|---|---|
| 客户需求访谈 | 部分能 | 辅助整理 | 真实意图、承诺边界、优先级判断 |
| 技术资料调研 | 能 | 很适合 | 检查来源、提炼路线、识别盲点 |
| 显存/性能估算 | 能 | 适合草算 | 公式口径、硬件边界、实测解释 |
| 代码穿刺 | 能 | 适合辅助 | 最小假设、测试设计、结果验收 |
| 每日进展跟踪 | 能 | 很适合 | 判断阻塞是否真实、谁需要介入 |
| 周报/月报 | 能 | 适合草拟 | 取舍、风险措辞、必要求助 |
| 投产决策 | 不宜外包 | 只能辅助 | 责任归属、风险接受、回滚方案 |
每日跟踪¶
多局点工作最容易失控的地方,是 没有每天更新每个人力进展。进展不是“今天也在做”,而是能回答:
- 交付物是什么:代码、数据、报告、实验结果、客户确认、投产脚本。
- 当前卡点是什么:技术不确定、资源不足、依赖未响应、需求不清、环境不可用。
- 下一步动作是什么:今天谁做、做到什么状态、什么时候反馈。
- 是否需要升级:是否需要我推动、找人、汇报、拒绝或改计划。
我的每日跟踪模板可以固定成:
日期:
主线目标:
P0 风险局点:
- 局点:
当前证据:
今日动作:
owner:
需要帮助:
P1 优势局点:
- 局点:
穿刺结果:
下一步:
可汇报进展:
人力进展:
- 人员/方向:
交付物:
阻塞:
下一次同步时间:
AI 可加速项:
- 调研:
- 草稿:
- 建模:
- 记录:
风险和求助:
- 后续风险:
- 必要求助:
这个模板的关键不是格式,而是让每个局点每天都有 证据、动作、owner 和求助条件。
汇报方式¶
多汇报不是增加存在感,而是降低组织的不确定性。高质量汇报应该让上游知道三件事:
- 优势进展:我们已经解决了什么关键不确定性,形成了什么判断、模型、报告或可复用资产。
- 后续风险:接下来最可能失败在哪里,失败会影响什么窗口,当前有哪些缓解动作。
- 必要求助:需要谁、什么资源、什么决策、什么客户澄清,以及最晚什么时候需要。
我会用一个固定汇报结构:
汇报口径
不要只汇报“我做了很多”。要汇报 局点为什么重要、我推进了什么阻塞、当前优势在哪里、还缺什么支持。这样上游看到的是全局进展,而不是任务流水账。
记录与修正¶
历史记录是这套系统的复利来源。没有记录,就只能靠记忆和情绪判断;有记录,才能知道自己在哪些地方判断准、在哪些地方过度乐观、哪些风险总是被低估。
每个重要局点结束后,至少补一条复盘:
- 原始判断:当时为什么认为它重要。
- 关键证据:用了哪些数据、客户反馈、profile、实验或代码路径。
- 实际结果:是否投产、是否延期、是否被推翻。
- 得失原因:判断准在哪里,错在哪里。
- 可复用规则:下次遇到类似局点,应该更早做什么。
这也是 AI 能继续加速的地方:AI 可以整理记录、抽取模式、生成报告、补齐 checklist,但 最后的得失判断必须由人写。因为真正变强的是判断模型,不是文档格式。
后续问题¶
这套工作系统还需要持续修正,尤其是五个问题:
- WIP 上限:同时推进多少 P0/P1 才不会压垮深度工作。
- 拒绝话术:如何礼貌拒绝低优先级任务,同时不损害协作关系。
- AI 验收:哪些 AI 产物必须人工复核,哪些可以直接进入草稿层。
- 模型校准:显存、MFU、投产收益和人力成本估算如何持续和实测对齐。
- 汇报节奏:哪些风险要当天报,哪些适合周报沉淀,哪些需要先穿刺再汇报。
总结¶
个人优势不是“什么都做”,而是 在多局点里稳定抓住最能改变结果的少数点。我的目标可以浓缩成一条链路:
AI 可以让调研、草稿、建模、代码穿刺、日报和报告更快,但它不能替代客户判断、优先级取舍、风险承担和投产决策。真正的工作方式升级,是把 AI 变成系统的一部分,同时把人的判断力放到更高杠杆的位置。
参考文献¶
-
John D. C. Little, A Proof for the Queuing Formula: L = λW, Operations Research, 1961. ↩
-
Sophie Leroy, Why is it so hard to do my work? The challenge of attention residue when switching between work tasks, Organizational Behavior and Human Decision Processes, 2009. ↩
-
Hirotaka Takeuchi and Ikujiro Nonaka, The New New Product Development Game, Harvard Business Review, 1986. ↩
-
Aakanksha Chowdhery et al., PaLM: Scaling Language Modeling with Pathways, arXiv, 2022. ↩
-
Sida Peng et al., The Impact of AI on Developer Productivity: Evidence from GitHub Copilot, arXiv, 2023. ↩
-
Shakked Noy and Whitney Zhang, Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence, Science, 2023. ↩
-
Erik Brynjolfsson, Danielle Li, and Lindsey R. Raymond, Generative AI at Work, NBER Working Paper, 2023. ↩
-
Samuel Camou et al., The Impact of Generative AI on Programming Education and Industry: A Meta-analysis of Controlled Experiments, arXiv, 2026. ↩