Disordered Ideas
- What'sNext 副业。量化金融,落地快:1.每一次策略的修改都直接影响下一次能不能赚钱;性能优化也是。
-
Bigger 量化金融,负责资金统一管理。adapator,股票,证券,期货,外汇
-
自动交易工具:数据接口,交易接口
重要说明:
这里存放着未被整理、分类,和仔细对比讨论过的 ideas。
Bigger 量化金融,负责资金统一管理。adapator,股票,证券,期货,外汇
自动交易工具:数据接口,交易接口
这里存放着未被整理、分类,和仔细对比讨论过的 ideas。
导言
"Balancing work and personal life is the cornerstone of a successful and productive career."
| 230910 | 230922 | |
|---|---|---|
| Neck | 39cm | |
| bust | 89cm | |
| the whole body | 110cm | |
| waist | 84cm | |
| hipline | 95cm | |
| Upper Arm Circumference | 27cm | |
| Forearm circumference | 23.4cm | |
| Thigh Girth | 57cm | 54.6cm |
| calf Grith | 38.4cm | 36.5cm |
| weight | 65.4kg | 65.9kg |
这个说得很在点子上,我是在19年末的时候通过改变走路发力方式瘦小腿的。与其说瘦腿,其实更是和大腿相比看起来更匀称,我之前的小腿肚站起来时候和大腿一样粗,站直的时候膝盖甚至是合不上的。经过反思,发现我日常走路的时候时间长了经常会感到小腿酸胀,这其实一直是在用小腿走路,我在这期间尝试过跑步,虽小有成效,但停下来就又会恢复原状。这种情况导致的小腿粗是一个比较复杂的原理,但我最后通过大半年的时间对走路方式进行了调整,现在虽然小腿不算细,但和大腿比起来看起来已经相当正常了,我的调整策略如下: 走路时注意重心靠后,也就是后背中间的位置,同时双肩放松,这样你会不自觉地挺胸抬头,同时为保持平衡感觉到腹部有牵引感。走路时大腿内侧和屁股发力,重点来了:保持脚后跟尽量贴住地面(踮脚走路是大忌),迈步时脚后跟先接触地面,在前脚后跟接触地面之前,后脚后跟不要离开地面。简单来说就是用脚后跟走路,你会发现这个过程中小腿是几乎不怎么发力的,时间久了只要不是肥胖型自然会瘦下来。
漫画或者PDF的jellyfin版本 , 类似的还有 基于docker的smanga
Rather than browse rouman online, high-resolution pivix pictures seems more worthy to be downloaded and maintained.
But first you need a much bigger NAS.
image run创建容器。data/1 and data/2。 and Please think carefully because restart container will triger the following bugs:
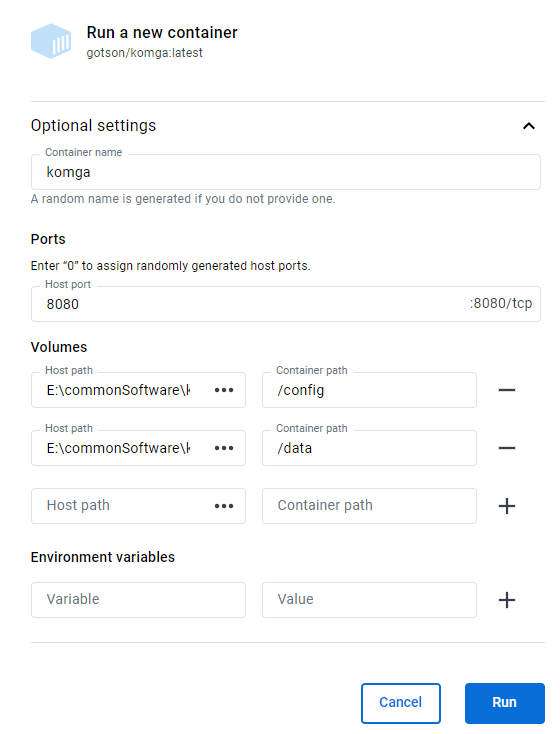
But docker on Windows remains many bugs:
In http://brainiac.acsalab.com:2333/
sudo mount.cifs //synology.acsalab.com/Entertainment /synology -o user=xxx vers=3.0采取第一种, 在 portainer.io的local的stack里使用docker compose部署
---
version: '3.3'
services:
komga:
image: gotson/komga
container_name: komga
volumes:
- type: bind
source: /mnt/e/commonSoftware/komga/config # Database and Komga configurations
target: /config
- type: bind
source: /mnt/e/commonSoftware/komga/data # Location of your data directory on disk. Choose a folder that contains both your books and your preferred import location for hardlinks to work.
target: /data/komga
- type: bind
source: /etc/timezone #alternatively you can use a TZ environment variable, like TZ=Europe/London
target: /etc/timezone
read_only: true
ports:
- 2333:8080 # 应用内部的 8080 到机器的2333端口。由于机器的8080被qBit占用了
user: "1000:1000"
# remove the whole environment section if you don't need it
environment:
- <ENV_VAR>=<extra configuration>
restart: unless-stopped
komga image需要图书/漫画刮削
有封面图和备注详细角色和类型信息。
| dockers | komga | smanga | Kavita |
|---|---|---|---|
| 单一大PDF文件加载 | 缓慢 | 缓慢 | |
| 格式支持 | zip,cbz,pdf | 部分zip不支持bug,不支持cbz | zip,pdf ,cbz |
| 如何支持单文件夹多图片 | 每个文件夹单独压缩成zip反而支持 | ||
| 自定义元数据 | |||
| 任意位置标签 | |||
| 已知bug | 容器会自动关机(有待进一步测试) | ||
| 总体评价 | 基础完善稳定,但是定制化不足 | 有用的定制化 | 全,但是不维持原目录有点恶心,导致必须按照类型整理。 |
"Manga" 和 "comic" 是两个术语,通常用于描述不同地区和文化中的漫画,其中 "manga" 常用于日本漫画,而 "comic" 通常用于西方漫画,包括美国漫画。
特点: Manga 的特点包括从右到左的阅读顺序,经常包含有关日本文化和社会的元素,以及广泛的主题和风格。
Comic(漫画):
需要注意的是,"manga" 和 "comic" 不仅仅是描述漫画的词汇,它们还代表了不同的创作风格、文化和产业。虽然在某些上下文中可能会使用这两个词汇来泛指漫画,但在讨论时最好根据具体的地域和文化使用适当的术语。
Series Name的新文件(e.g.,abc.cbz),当作新的作品单独列出在根目录。这十分傻逼,对内容的共振度的要求也太高了。出现一个命名不规范的文件就会乱套。可以看得出作者有特殊的设计。
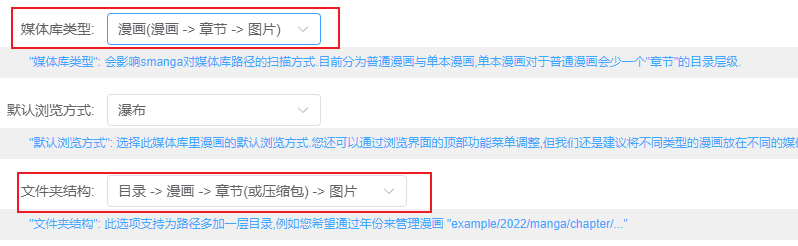
但是美中不足的是对于子文件夹的支持不够,太深的文件读取不到。
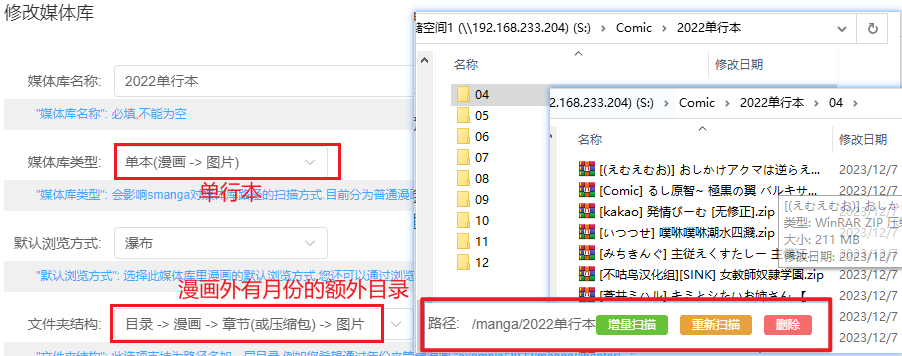
理论如此,但是实际貌似会卡住。
Komga支持CBZ/CBR、EPUB、PDF格式。对于漫画而言,个人觉得cbz1是最简单、兼容性最高的格式。
建议的文件结构如下:
.
└── libraryManga
├── 我 推 的 孩 子
│ ├── 第 1话.cbz
│ └── 第 9话 .cbz
└── 辉夜大小姐想让我告白
├── 01话 .cbz
└── 02话.cbz
3 directories, 4 files
libraryManga表示库名,下一层结构区分不同的漫画,更下一层则存储漫画文件内容的组织考虑的是一个平衡,每个lib下应该只有40个左右的内容。
下载的内容的特点:
合集/A/PDF/* 看多少,刮削多少。
见 Calibre and its Pugins for e-hentai Books 一文
cbl,配置好后在目录下运行python processMetadata.py,即可近乎完美的给漫画加上海报和信息了尝试后发现是,类似RSS的漫画网页集成浏览器(B站,腾讯漫画,18+漫画)。实现订阅,跟踪,一键下载。 由于生态很不错,不用担心订阅链接失效。
我猜测是内存不够
[Kavita] [2023-12-08 07:21:00.508 +00:00 194] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP GET /api/image/series-cover?seriesId=759&apiKey=39714029-85f9-446c-9834-9ad384fda00d responded 304 in 0.9718 ms
[Kavita] [2023-12-08 07:21:50.010 +00:00 188] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP POST /api/account/refresh-token responded 200 in 2630.1327 ms
[Kavita] [2023-12-08 07:21:50.043 +00:00 193] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP GET /api/license/valid-license?forceCheck=false responded 200 in 17.1837 ms
[Kavita] [2023-12-08 07:21:50.045 +00:00 182] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP POST /hubs/messages/negotiate?negotiateVersion=1 responded 200 in 5.7189 ms
[Kavita] [2023-12-08 07:21:50.131 +00:00 168] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP GET /api/device responded 200 in 107.7960 ms
Server is shutting down. Please allow a few seconds to stop any background jobs...
You may now close the application window.
[Kavita] [2023-12-08 07:21:55.785 +00:00 179] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP POST /hubs/messages/negotiate?negotiateVersion=1 responded 200 in 0.1795 ms
[Kavita] [2023-12-08 07:21:55.789 +00:00 45] [Information] Microsoft.Hosting.Lifetime Application is shutting down...
[Kavita] [2023-12-08 07:22:26.562 +00:00 179] [Fatal] Host terminated unexpectedly
System.AggregateException: One or more hosted services failed to stop. (The operation was canceled.)
---> System.OperationCanceledException: The operation was canceled.
at System.Threading.CancellationToken.ThrowOperationCanceledException()
at System.Threading.CancellationToken.ThrowIfCancellationRequested()
at Hangfire.Processing.TaskExtensions.WaitOneAsync(WaitHandle waitHandle, TimeSpan timeout, CancellationToken token)
at Hangfire.Processing.BackgroundDispatcher.WaitAsync(TimeSpan timeout, CancellationToken cancellationToken)
at Hangfire.Server.BackgroundProcessingServer.WaitForShutdownAsync(CancellationToken cancellationToken)
at Microsoft.Extensions.Hosting.Internal.Host.StopAsync(CancellationToken cancellationToken)
--- End of inner exception stack trace ---
at Microsoft.Extensions.Hosting.Internal.Host.StopAsync(CancellationToken cancellationToken)
at Microsoft.Extensions.Hosting.HostingAbstractionsHostExtensions.WaitForShutdownAsync(IHost host, CancellationToken token)
at Microsoft.Extensions.Hosting.HostingAbstractionsHostExtensions.RunAsync(IHost host, CancellationToken token)
at Microsoft.Extensions.Hosting.HostingAbstractionsHostExtensions.RunAsync(IHost host, CancellationToken token)
at API.Program.Main(String[] args) in /home/runner/work/Kavita/Kavita/API/Program.cs:line 115
查看对应docker日志, 猜测容器运行时,可能会受到资源限制,例如内存不足、CPU 使用过高等。如果容器超过了资源限制,可能会被系统强制关闭。
2023-12-07T11:28:39.022Z INFO 1 --- [taskProcessor-4] o.g.komga.application.tasks.TaskHandler : Task FindBooksWithMissingPageHash(libraryId='0EEB1WDMHPFT0', priority='0') executed in 722.922us
2023-12-07T11:28:39.080Z INFO 1 --- [taskProcessor-4] o.g.komga.application.tasks.TaskHandler : Executing task: FindDuplicatePagesToDelete(libraryId='0EEB1WDMHPFT0', priority='0')
2023-12-07T11:28:39.096Z INFO 1 --- [taskProcessor-4] o.g.komga.application.tasks.TaskEmitter : Sending tasks: []
2023-12-07T11:28:39.096Z INFO 1 --- [taskProcessor-4] o.g.komga.application.tasks.TaskHandler : Task FindDuplicatePagesToDelete(libraryId='0EEB1WDMHPFT0', priority='0') executed in 16.090346ms
2023-12-07T13:38:16.408Z INFO 1 --- [ionShutdownHook] o.s.b.w.e.tomcat.GracefulShutdown : Commencing graceful shutdown. Waiting for active requests to complete
2023-12-07T13:38:16.638Z INFO 1 --- [tomcat-shutdown] o.s.b.w.e.tomcat.GracefulShutdown : Graceful shutdown complete
2023-12-07T13:38:18.871Z INFO 1 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : SqliteTaskPool - Shutdown initiated...
2023-12-07T13:38:18.883Z INFO 1 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : SqliteTaskPool - Shutdown completed.
2023-12-07T13:38:18.887Z INFO 1 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : SqliteUdfPool - Shutdown initiated...
2023-12-07T13:38:18.889Z INFO 1 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : SqliteUdfPool - Shutdown completed.
____ __.
| |/ _|____ _____ _________
| < / _ \ / \ / ___\__ \
| | ( <_> ) Y Y \/ /_/ > __ \_
|____|__ \____/|__|_| /\___ (____ /
\/ \//_____/ \/
Version: 1.8.4
暂无
暂无
https://sspai.com/post/79100
人的精力是有限的,投入到自己喜欢或者为生的事情上,其他的事情,专业的事情交给专业的人
简介
工作回顾,当前工作,未来展望
简介
工作回顾,当前工作,未来展望
秋招篇
| 命令 | 描述 |
|---|---|
next |
单步执行 |
step |
单步进入 |
finish or fin |
跳出当前函数 |
continue |
继续执行到下一个断点 |
until |
继续运行到指定位置 |
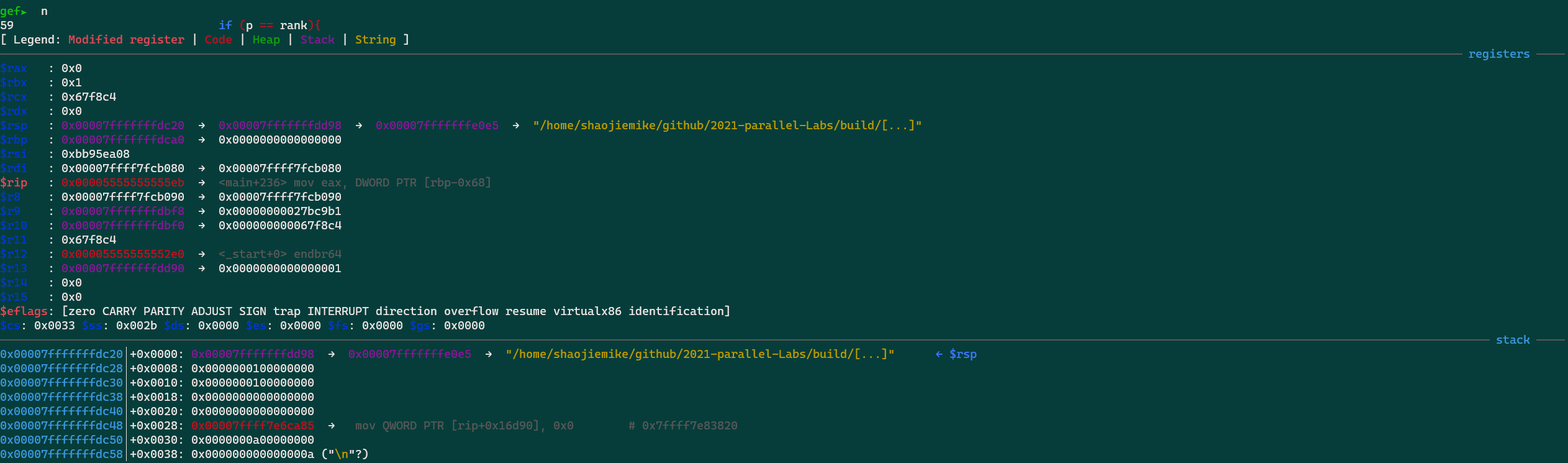
finish: Continue running until just after function in the selected stack frame returns. Print the returned value (if any). gdb --args 正常程序+参数set args 参数f 打印当前文件 ,便于打断点info breakpoints 查看已经的断点del 3 删除NUM=3的第三个断点给某个结构体内的函数全部上break
show argsinfo localsp result=20btinfo threadsthread 2thread apply all btgef➤ p -raw-values off -- this->TotalCycles
gef➤ p this
$11 = (llvm::mca::SummaryView * const) 0x7fffffffcc08
gef➤ p *this
p **matrix@3@3p *matrix@3p *(int *)matrix@3p *(int (*)[3])matrix可以看到打印了array数组第60~69个元素的值。如果要打印从数组开头连续元素的值,也可使用这个命令:“p *array@num”:
格式:x /nfu <addr>
说明:
x 是 examine 的缩写。n 表示要显示的内存单元的个数。f 表示显示方式,可取如下值:| 显示方式 | 描述 |
|---|---|
x |
按十六进制格式显示变量。 |
d |
按十进制格式显示变量。 |
u |
按无符号整型格式显示变量。 |
o |
按八进制格式显示变量。 |
t |
按二进制格式显示变量。 |
a |
按十六进制格式显示变量。 |
i |
指令地址格式。 |
c |
按字符格式显示变量。 |
f |
按浮点数格式显示变量。 |
u 表示一个地址单元的长度,长度类型如下:| 类型 | 描述 |
|---|---|
b |
单字节 |
h |
双字节 |
w |
四字节 |
g |
八字节 |
example:
(gdb) x 0x8049948
0x8049948: 0x20726f46
(gdb) x/s 0x8049948
0x8049948: "For NASA,space is still a high priority."
(gdb) x/4 0x7fffe536dbc0 # display 4 bytes info?
0x7fffe536dbc0: 0x0 0x0 0x9d835 0x0
段错误定位
# ulimit -c 显示核心转储文件大小的最大值
ulimit -c unlimited # 打开
ulimit -c 0 # 关闭
# 改变core存储位置
#%e 打印线程name
#%p 打印进程id
#%h 打印主机名
#%t 打印时间
echo '/tmp/core-%e.%p.%h.%t' > /proc/sys/kernel/core_pattern
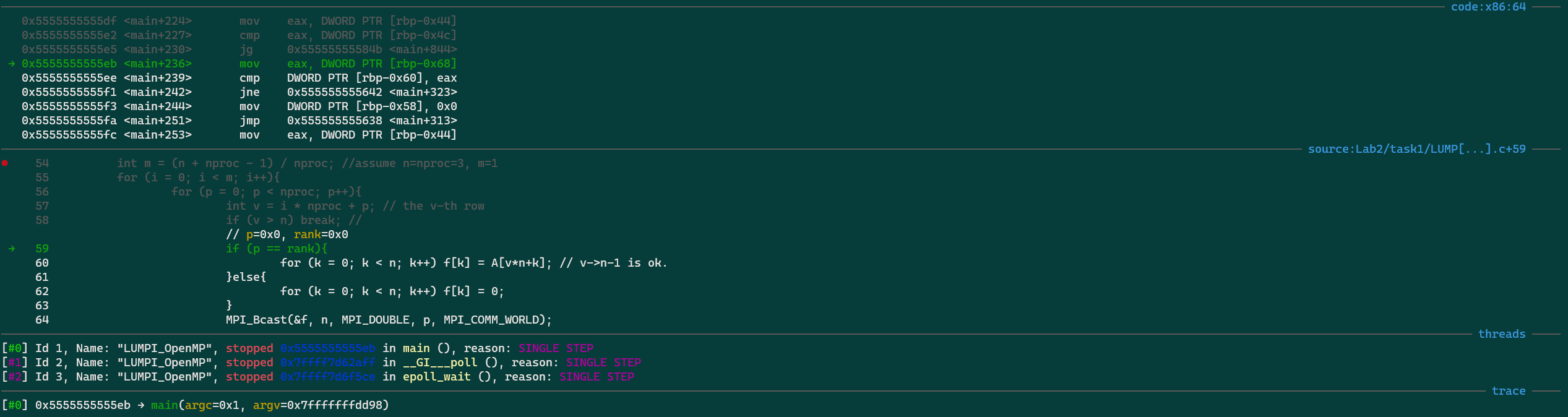
(gdb) bt
#0 0x00002af6047e4a4b in fgets () from /lib64/libc.so.6
#1 0x000000000040450a in LoadPPM (filename=0x407e63 "input_image.ppm", data=0x7ffecda55cc8, width=0x7ffecda55cc4, height=0x7ffecda55cc0) at SLIC_raw.cpp:692
#2 0x00000000004049e1 in main (argc=1, argv=0x7ffecda55de8) at SLIC_raw.cpp:794
python 程序
会打印详细的信息
需要GDB10以上
bash -c "$(curl -fsSL http://gef.blah.cat/sh)"
# 没有网,手动下 https://gef.blah.cat/py ,替换
$ wget -O ~/.gdbinit-gef.py -q https://gef.blah.cat/py
$ echo source ~/.gdbinit-gef.py >> ~/.gdbinit
注意:gdbtui 与 gef 不太兼容
导言
我想写关于 linux 网络命令 ip iptables ufw 的相关文档来全面表述linux网络的构成和如何控制管理
基本是基于Linux的时间片轮转机制。A process/thread is woken up by inserting it in the queue of processes/threads to be scheduled.
CFS(Completely Fair Scheduler)是一种用于 Linux 操作系统的调度算法,它旨在实现对 CPU 时间的公平分配。CFS 是 Linux 内核中默认的调度器,自 Linux 2.6.23 版本以来就成为了标准调度器。
CFS 调度算法的主要目标是确保各个任务在相同的时间片内能够获得公平的CPU时间,不会因为优先级等因素而造成资源争夺不均。以下是 CFS 调度算法的一些关键特点和原则:
虚拟化时钟: CFS 使用了一种称为虚拟化时钟(virtual runtime)的概念,而不是传统的时间片。每个任务都有一个虚拟运行时间,调度器根据虚拟运行时间来决定哪个任务应该被调度。
权重: CFS 引入了权重的概念,用于调整不同任务的相对优先级。较高权重的任务会在相同时间间隔内获得更多的虚拟运行时间,从而实现按比例分配CPU资源。
累积虚拟运行时间: 调度器会根据每个任务的权重和已累积的虚拟运行时间,计算出每个任务的应有的虚拟运行时间片。任务在使用完它的时间片后,会根据虚拟运行时间进行重新排队。
红黑树结构: CFS 使用红黑树来管理任务队列,这种数据结构使得在插入、删除和搜索任务时的时间复杂度保持在对数级别。
除了 CFS,Linux 内核还有其他调度算法,如:
实时调度器(Real-Time Scheduler): 用于实时任务,提供硬实时和软实时的调度策略,确保实时任务在指定的时间内执行完成。
O(1) 调度器(O(1) Scheduler): 是 Linux 2.4 内核中使用的调度器,它的时间复杂度为常数级别。然而,随着多核系统的出现,O(1) 调度器在多核环境下的性能表现受到限制,因此被 CFS 替代。
这些调度算法在不同的场景和需求下,对于多任务操作系统的调度提供了不同的方法和策略。选择适合的调度算法可以根据系统的应用和性能要求来进行。
在高强度竞争之后,有些进程陷入长期sleep,并且在核空闲的时候,也不再重新运行?为什么?
原因可能是程序逻辑阻塞了,或者在等待IO
首先 计算机对一个进程是如何判断sleep的,是某时间内的计算占比低于某个阈值吗?
htop s 可以查看kernel 是不是阻塞, l 可以查看是不是读写同一个文件导致阻塞了。
Sleep的瓶颈在哪里
sleep for what, waiting for what?
strace -p PID 可以显示一些信息
$ strace -p 4005042
wait4(-1, # 等待任意子进程结束
# check subprocess
$ pstree -p 4005042
pinbin(4005042)---BC_Compute(4005082)-+-{BC_Compute}(4005187)
|-{BC_Compute}(4005188)
|-{BC_Compute}(4005252)
|-{BC_Compute}(4005296)
|-{BC_Compute}(4005299)
`-{BC_Compute}(4005302)
$ strace -p 4005082
strace: Process 4005082 attached
futex(0x7fffe52de1b8, FUTEX_WAIT, 2, NULL
# futex - fast user-space locking(seems to be used in OpenMP)
# It is typically used as a blocking construct in the context of shared-memory synchronization.
$ strace -p 4005188
nanosleep({tv_sec=0, tv_nsec=2000000}, 0x7fffe5368bc0) = 0 # repeat
nanosleep({tv_sec=0, tv_nsec=2000000}, 0x7fffe536dbc0) = 0
It seems this is a subprocess repeating sleep leading to all other process to wait in the synchronization.
Use gdb -p PID to attach the process to locate the infinite loop (need Debug Symbols).
futex 是 Linux 下的一个系统调用,用于实现用户空间线程间的同步和通信。让我们逐个解释这个系统调用中的每个参数的含义:
0x7fffe52de1b8: 这是一个指向内存地址的指针(或称为地址),通常是用于表示需要同步的资源或变量的地址。在这里,它表示需要等待的共享资源或变量的地址。FUTEX_WAIT: 这是一个指定 futex 要执行的操作的标志。FUTEX_WAIT 表示线程正在等待 futex 的值发生变化,即等待条件满足。当某个线程执行 FUTEX_WAIT 操作时,如果 futex 的值与预期不符,则该线程将被置于休眠状态,直到 futex 的值发生变化或超时。2: 这是一个表示期望的 futex 值的参数。当调用 FUTEX_WAIT 时,线程将检查 futex 的当前值是否等于此参数指定的值。如果不等于,则线程将休眠等待。NULL: 这是一个指向 timespec 结构的指针,用于设置超时。这里为 NULL 表示调用没有设置超时,即线程将一直等待,直到 futex 的值发生变化。总的来说,futex(0x7fffe52de1b8, FUTEX_WAIT, 2, NULL) 表示线程正在等待位于内存地址 0x7fffe52de1b8 的 futex 变量的值等于 2。如果 futex 的值不是 2,则线程将一直等待直到 futex 的值变为 2 或者超时。这样的同步机制在多线程编程中用于等待条件满足后再执行某些操作,从而避免资源竞争和提高程序的并发性能。
这是一个系统调用 nanosleep 的输出,通常用于让线程休眠一段时间。让我们逐个解释这个系统调用的含义:
nanosleep: 这是 Linux 下的一个系统调用,用于使线程休眠一段指定的时间。
{tv_sec=0, tv_nsec=2000000}: 这是传递给 nanosleep 的第一个参数,是一个指向 timespec 结构的指针。timespec 结构用于表示时间间隔,包括秒(tv_sec)和纳秒(tv_nsec)。
在这里,tv_sec=0 表示秒数为 0,tv_nsec=2000000 表示纳秒数为 2000000。因此,这个 nanosleep 调用将会使线程休眠 2 毫秒(1 秒 = 1000000000 纳秒,所以 2000000 纳秒就是 2 毫秒)。
0x7fffe5368bc0: 这是传递给 nanosleep 的第二个参数,表示一个 timespec 结构的指针。这个参数用于存放未休眠完成的剩余时间,如果 nanosleep 被中断(例如收到信号),它将在这个指针中返回剩余的时间。在这个输出中,剩余时间被存储在内存地址 0x7fffe5368bc0 处。
= 0: 这是 nanosleep 的返回值,表示成功完成。返回值为 0 表示 nanosleep 成功休眠了指定的时间。
综上所述,这个输出表示线程成功休眠了 2 毫秒。
程序直接执行正常,zsim模拟直接sleep?
$ strace -p 303359
read(10,
$ pstree -p 303359 │
gups_vanilla(303359)-+-gups_vanilla(303449)-+-orted+ │
| `-{gups+ │
|-{gups_vanilla}(303360) │
|-{gups_vanilla}(303361)
$ pstree -p 303449 │
gups_vanilla(303449)-+-orted(303451)-+-{orted}(303452) │
| |-{orted}(303642) │
| |-{orted}(303643) │
| `-{orted}(303644) │
`-{gups_vanilla}(303450)
这是一个 Open MPI(Message Passing Interface)的启动命令,用于启动一个 MPI 程序,并配置一些运行时参数。让我们逐个解释这个命令中的每个选项和参数的含义:
orted --hnp --set-sid --report-uri 11 --singleton-died-pipe 12 -mca state_novm_select 1 -mca ess hnp -mca pmix ^s1,s2,cray,isolated
部分参数含义如下:
orted: 这是 Open MPI 的一个工具,用于启动和管理 MPI 进程。-mca state_novm_select 1: 这是一个 MCA(Modular Component Architecture)选项,用于指定某个模块或组件的参数设置。在这里,state_novm_select 设置为 1,可能是指定某个组件或模块在运行时的选项。-mca pmix ^s1,s2,cray,isolated: 这是另一个 MCA 选项,用于配置 PMIx(Process Management Interface for Exascale)的相关设置。^s1,s2,cray,isolated 表示排除 s1、s2、cray 和 isolated 这些模块,可能是禁用某些特定的组件或功能。| pid | strace output | explanation |
|---|---|---|
| 303451 | restart_syscall(<... resuming interrupted read ...> | |
| 303452 | futex(0xabba001ec8, FUTEX_WAIT, 2, NULL | |
| 303642 | epoll_wait(18, ... | epoll_wait 系统调用,用于等待文件描述符18上的事件 |
| 303643 | select(50, [48 49], NULL, NULL, | 如下 |
| 303644 | select(53, [51 52], NULL, NULL, |
restart_syscall表示系统调用被中断后重新启动的过程。它通常出现在系统调用的执行过程中,当某个信号(例如 SIGSTOP 或 SIGCONT)中断了系统调用的执行,然后系统调用在信号处理完成后被重新启动。The only way to “wake it up” is to arrange for the condition to be met. 用户是无法更改的状态的。
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无