1.1 Living Needs & Meaning
have merged 2 topdown site
have merged 2 topdown site
login to free SMTP server(qq, google) to send email to others.
ping mail.ustc.edu.cnAccording to ref1.
send but the same, more crazy thing is the -v and -d flag is not supported. and --debug-level=trace0 isn't recognized. many same question in StackOverflow
sudo tail -n 30 /var/log/mail.log or mail.error show more info.
We try ref2 ssmtp, sudo vim /etc/ssmtp/ssmtp.conf
TLS_CA_FILE=/etc/pki/tls/certs/ca-bundle.crt
root=shaojieemail@gmail.com
mailhub=smtp.gmail.com:587
rewriteDomain=gmail.com
AuthUser=shaojieemail
AuthPass={apppassword}
FromLineOverride=YES
UseSTARTTLS=Yes
UseTLS=YES
hostname=snode6
The config get work but not well configed, e.g., TLS_CA_FILE
sending a email using gmail took about 13 mins.
$ ssmtp 943648187@qq.com < mail.txt
......
[->] Received: by snode6 (sSMTP sendmail emulation); Wed, 06 Sep 2023 15:42:05 +0800
[->] From: "Shaojie Tan" <shaojiemike@gmail.com>
[->] Date: Wed, 06 Sep 2023 15:42:05 +0800
[->] test server email sending
[->]
[->] .
[<-] 250 2.0.0 OK 1693986323 5-20020a17090a1a4500b0026b4ca7f62csm11149314pjl.39 - gsmtp
[->] QUIT
[<-] 221 2.0.0 closing connection 5-20020a17090a1a4500b0026b4ca7f62csm11149314pjl.39 - gsmtp
$ sendmail 94364818s7@qq.com < mail.txt
sendmail: Authorization failed (535 5.7.8 https://support.google.com/mail/?p=BadCredentials e7-20020a170902b78700b001c0c79b386esm8725297pls.95 - gsmtp)
get to work after well config gmail setting.
| command | snode6 time(mins) | icarus1 |
|---|---|---|
| 4 | 1s | |
| ssmtp | 13 | |
| sendmail | 6 |
ref using QQ apppassword and python.
cpu_check.sh:#!/bin/bash
# Get CPU usage percentage
cpu_usage=$(top -b -n 1 | grep '%Cpu(s):' | awk '{print $2}' | cut -d'.' -f1)
echo "cpu_usage : ${cpu_usage} on $(hostname)"
# Check if CPU usage is below 30%
if [ "$cpu_usage" -lt 30 ]; then
echo "beyond threshold : ${cpu_usage} on "
# Send an email
echo "CPU usage is ${cpu_usage} below 30% on $(hostname)" | mail -s "Low CPU Usage Alert on $(hostname)" your_email@example.com
fi
Make the script executable:
Modify your_email@example.com with your actual email address.
cron scheduler to run the script at regular intervals. Edit your crontab by running:Add an entry to run the script, for example, every 5 minutes:
*/5 * * * * /staff/shaojiemike/test/cpu_check.sh >> /staff/shaojiemike/test/cpu_check.log
# Run every 15 minutes during working hours (9 am to 7 pm)
*/15 9-19 * * * /path/to/your/script.sh
Replace /path/to/cpu_check.sh with the actual path to your Bash script.
Now, the script will run every 5 minutes (adjust the cron schedule as needed) and send an email notification if the CPU usage is below 50%. You should receive an email when the condition is met.
Please note that this is a basic example, and you can modify the script to include more details or customize the notification further as needed. Additionally, ensure that your server is configured to send emails; you may need to configure SMTP settings for the mail or sendmail command to work correctly.
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
Anaconda和Miniconda都是针对数据科学和机器学习领域的Python发行版本,它们包含了许多常用的数据科学包和工具,使得安装和管理这些包变得更加简单。
解决了几个痛点:
Anaconda是一个全功能的Python发行版本,由Anaconda, Inc.(前称Continuum Analytics)提供。
Miniconda是Anaconda的轻量级版本(50MB),它也由Anaconda, Inc.提供。
According to the official website,
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
# choose local path to install, maybe ~/.local
# init = yes, will auto modified the .zshrc to add the miniconda to PATH
# If you'd prefer that conda's base environment not be activated on startup,
# set the auto_activate_base parameter to false:
conda config --set auto_activate_base false
you need to close all terminal(all windows in one section including all split windows), and reopen a terminal will take effect;
Python on windows1
CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://repo.anaconda.com/pkgs/main/linux-64/repodata.json>面对如下报错
> conda create -n opensora-t00906153 python=3.8 -y
Channels:
- defaults
Platform: linux-64
Collecting package metadata (repodata.json): failed
CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://repo.anaconda.com/pkgs/main/linux-64/repodata.json>
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
If your current network has https://repo.anaconda.com blocked, please file
a support request with your network engineering team.
'https//repo.anaconda.com/pkgs/main/linux-64'
修改~/.condarc
ssl_verify: true
show_channel_urls: true
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- conda-forge
如果还是有超时错误,多半是下载多了被拦截
通过 curl -v http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ 检查是不是请求被阻拦了。
可以换成科大源或者default 源。
# 激活环境(base),路径为指定的 conda 安装路径下的 `bin/activate` 文件
source /home/m00876805/anaconda3/bin/activate
# 或者 conda init zsh
# 使用以下命令创建一个名为"myenv"的虚拟环境(您可以将"myenv"替换为您喜欢的环境名称):
conda create --name myenv python=3.8
# list existed env
conda env list
/home/m00876805/anaconda3/bin/conda env list
# 查看具体环境的详细信息
conda env export --name <env_name>
# 激活,退出
conda activate name
conda deactivate name
conda packconda pack 用于将现有的 Conda 环境打包成一个压缩文件(如 .tar.gz),便于在其他系统上分发和安装。conda-unpack 来修复路径,使其在新环境中正常工作。conda-pack 可以将 Conda 环境打包成一个 .tar.gz 文件,以便于跨机器或系统移动和还原环境。以下是使用 conda-pack 打包和还原环境的步骤:
假设要打包的环境名为 my_env:
这会在当前目录生成一个 my_env.tar.gz 文件。你可以将这个文件复制到其他系统或机器上解压还原。
在一个特定的 conda 环境目录(例如 /home/anaconda3)下还原和激活打包的环境,可以按以下步骤操作:
假设场景
conda 激活路径:/home/anaconda3/bin/activatemy_env.tar.gzmy_env步骤
conda 环境目录首先,将打包文件解压到指定的 conda 环境目录下的 envs 目录:
mkdir -p /home/anaconda3/envs/my_env
tar -xzf my_env.tar.gz -C /home/anaconda3/envs/my_env --strip-components 1
这里的 --strip-components 1 会去掉 tar.gz 包中的顶层目录结构,使内容直接解压到 my_env 文件夹内。
激活该环境,并运行 conda-unpack 来修复路径:
现在,my_env 环境已在 /home/anaconda3 目录下的 envs 文件夹中完成还原,可以正常使用。
conda env exportconda env export > freeze.yml 用于导出当前 Conda 环境的配置,包括所有安装的包和它们的版本信息,以 YAML 格式保存。conda env create -f freeze.yml 可以根据导出的 YAML 文件创建一个新环境。conda list -e > requirements.txt 和 conda env export > freeze.yml
conda list -e > requirements.txt 和 conda env export > freeze.yml 都是用于记录和管理 Conda 环境中安装的包,但它们之间有一些关键的区别:
conda list -e
requirements.txt)。conda install --yes --file requirements.txt 可以尝试使用 Conda 安装这些列出的包。这种方式适合简单的包管理,但可能在处理复杂依赖时存在问题。conda env export
freeze.yml),它包含了当前环境的完整配置,包括所有包、版本、渠道等信息。conda env create -f freeze.yml 可以根据 YAML 文件创建一个新的环境,确保与原环境一致。关系与总结
conda env export 更加全面和可靠,适合重建相同的环境;而 conda list -e 更简单,适合快速记录包。freeze.yml 是更好的选择;而对于简单的包列表管理,requirements.txt 可能足够用。因此,如果你的目标是确保环境的一致性,使用 conda env export 和 freeze.yml 是推荐的做法;如果只是想快速记录并安装一组包,requirements.txt 是一个方便的选择。
在conda命令无效时使用pip命令来代替
while read requirement; do conda install --yes $requirement || pip install $requirement; done < requirements.txt
The double pipe (“||”) is a control operator that represents the logical OR operation. It is used to execute a command or series of commands only if the previous command or pipeline has failed or has returned a non-zero status code.
conda create -n 新环境名称 --clone 原环境名称 --copy
虽然是完全复制,但是pip install -e安装的包会因为源文件的改动而失效
pip install -e 是用于在开发模式下安装 Python 包的命令,允许你在不复制包文件的情况下,将项目源代码直接安装到 Python 环境中,并保持源代码与环境中的包同步更新。这对于开发过程中频繁修改和测试代码非常有用。
以下是 pip install -e 的使用方法:pip install -e /path/to/project
详细解释:
通过 pip freeze 命令更好地查看
pip freeze 命令更好地查看:如果你想明确区分哪些包是通过 pip install -e 安装的,可以使用 pip freeze 命令。与 pip list 不同,pip freeze 会将包的版本和安装源显示出来。对于 -e(editable mode)安装的包,pip freeze 会有特殊标记。
运行以下命令:
输出示例:
在这里,带有 -e 标记的行表示这个包是通过 pip install -e 安装的,后面跟的是包的源代码路径(例如 Git 仓库 URL 或本地路径),而不是直接列出包的版本号。
输出解析:
-e 标记:表示这个包是以开发模式安装的。
pip install 安装的包(不是开发模式),它们会以 包名==版本号 的形式列出。git URL 或本地路径:开发模式下安装的包会指向源代码的路径,通常是 git 仓库 URL 或本地路径(如果是通过本地文件系统安装的)。导言
对程序员来说,一个好用、易用的terminal,就是和军人手上有把顺手的好枪一样。
用户的环境变量和配置文件
在Linux系统中,用户的环境变量和配置文件可以在不同的节点生效。以下是这些文件的功能和它们生效的时机:
/etc/environment:
/etc/profile:
/etc/profile.d/:
/etc/profile读取和执行。/etc/profile相同,登录shell时执行。它使得系统管理员可以将不同的配置分散到多个文件中管理。/etc/bash.bashrc:
~/.profile:
~/.bashrc:
总结:
/etc/environment 和 /etc/profile 主要用于系统范围的环境变量设置,前者不会执行shell命令,后者会执行。/etc/profile.d/ 中的脚本作为 /etc/profile 的扩展,用于更灵活的管理配置。/etc/bash.bashrc 适用于所有用户的bash配置,但只针对非登录shell。~/.profile 和 ~/.bashrc 适用于单个用户,前者用于登录shell,后者用于非登录shell。通过这些文件,系统和用户可以灵活地设置和管理环境变量和shell配置,以满足不同的需求和使用场景。
| 符号 | ASCII码 | 意义 |
|---|---|---|
| \n | 10 | 换行NL: 本义是光标往下一行(不一定到下一行行首),n的英文newline,控制字符可以写成LF,即Line Feed |
| \r | 13 | 回车CR: 本义是光标重新回到本行开头,r的英文return,控制字符可以写成CR,即Carriage Return |
在不同的操作系统这几个字符表现不同:
在任意层级的SHELL配置文件里添加
写成bashrc的脚本命令
#YJH proxy
export proxy_addr=localhost
export proxy_http_port=7890
export proxy_socks_port=7890
function set_proxy() {
export http_proxy=http://$proxy_addr:$proxy_http_port #如果使用git 不行,这两个http和https改成socks5就行
export https_proxy=http://$proxy_addr:$proxy_http_port
export all_proxy=socks5://$proxy_addr:$proxy_socks_port
export no_proxy=127.0.0.1,.huawei.com,localhost,local,.local
}
function unset_proxy() {
unset http_proxy
unset https_proxy
unset all_proxy
}
function test_proxy() {
curl -v -x http://$proxy_addr:$proxy_http_port https://www.google.com | egrep 'HTTP/(2|1.1) 200'
# socks5h://$proxy_addr:$proxy_socks_port
}
# set_proxy # 如果要登陆时默认启用代理则取消注释这句
鼠标滚轮输出乱码
滚轮乱码,是tmux set mouse on的原因
进入tmux后退出,并运行reset即可
sudo后找不到命令
当你使用sudo去执行一个程序时,处于安全的考虑,这个程序将在一个新的、最小化的环境中执行,也就是说,诸如PATH这样的环境变量,在sudo命令下已经被重置成默认状态了。
添加所需要的路径(如 /usr/local/bin)到/etc/sudoers文件"secure_path"下
解决办法如下:
zsim-tlb simulate in icarus0
pinbin: build/opt/zsim.cpp:816: LEVEL_BASE::VOID VdsoCallPoint(LEVEL_VM::THREADID): Assertion `vdsoPatchData[tid].level' failed.
Pin app terminated abnormally due to signal 6.
VOID VdsoCallPoint(THREADID tid) {
//level=0,invalid
assert(vdsoPatchData[tid].level);
vdsoPatchData[tid].level++;
// info("vDSO internal callpoint, now level %d", vdsoPatchData[tid].level); //common
}
vDSO (virtual dynamic shared object) is a kernel machanism for exporting a carefully set kernel space routines (eg. not secret api, gettid() and gettimeofday()) to user
spapce to eliminate the performance penalty of user-kernel mode switch according to wiki. vDSO__vdso_getcpu() C library, and kernel will auto move it to user-spacevDSO overcome vsyscall(first linux-kernel machanism to accelerate syscall) drawback.vDSO have only four function enum VdsoFunc {VF_CLOCK_GETTIME, VF_GETTIMEOFDAY, VF_TIME, VF_GETCPU};// Instrumentation function, called for EVERY instruction
VOID VdsoInstrument(INS ins) {
ADDRINT insAddr = INS_Address(ins); //get ins addr
if (unlikely(insAddr >= vdsoStart && insAddr < vdsoEnd)) {
//INS is vdso syscall
if (vdsoEntryMap.find(insAddr) != vdsoEntryMap.end()) {
VdsoFunc func = vdsoEntryMap[insAddr];
//call VdsoEntryPoint function
//argv are: tid ,func(IARG_UINT32),arg0(LEVEL_BASE::REG_RDI),arg1(LEVEL_BASE::REG_RSI)
INS_InsertCall(ins, IPOINT_BEFORE, (AFUNPTR) VdsoEntryPoint, IARG_THREAD_ID, IARG_UINT32, (uint32_t)func, IARG_REG_VALUE, LEVEL_BASE::REG_RDI, IARG_REG_VALUE, LEVEL_BASE::REG_RSI, IARG_END);
} else if (INS_IsCall(ins)) { //call instruction
INS_InsertCall(ins, IPOINT_BEFORE, (AFUNPTR) VdsoCallPoint, IARG_THREAD_ID, IARG_END);
} else if (INS_IsRet(ins)) { //Ret instruction
INS_InsertCall(ins, IPOINT_BEFORE, (AFUNPTR) VdsoRetPoint, IARG_THREAD_ID, IARG_REG_REFERENCE, LEVEL_BASE::REG_RAX /* return val */, IARG_END);
}
}
//Warn on the first vsyscall code translation
if (unlikely(insAddr >= vsyscallStart && insAddr < vsyscallEnd && !vsyscallWarned)) {
warn("Instrumenting vsyscall page code --- this process executes vsyscalls, which zsim does not virtualize!");
vsyscallWarned = true;
}
}
INS_Address is from pin-kit, but INS_InsertCall is pin api.
.level is just show the level of nested vsyscall. I think comment the assert which trigerd when callfunc before entryfunc is just fun.
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
华为实习要结束了,作为二次元,在中国秋叶原怎么能不好好逛逛呢?
上海真是包容性极强的地方。原本内心对二次元的热爱,竟然这么多人也喜欢。不必隐藏,时刻伪装。可以暂时放松自我的感觉真好。
爱或者热爱是最浓烈的情感。对象一般是可以交互的人物,物体说不定也可以。但是至少要能与他持续产生美好的回忆和点滴,来支持这份情感。
比如说,我一直想让自己能热爱我的工作,就需要创造小的阶段成功和胜利来支持自己走下去。
三次元的人物包括偶像歌手,和演员。需要演出,演唱会来与粉丝共创回忆,演员也需要影视剧作品。
二次元人物大多数来自于动画,因为游戏一般不以刻画人物为目的,比如主机游戏 当然galgame和二次元手游除外。
日本动画以远超欧美和国创的题材和人物的细腻刻画(不愧是galgame大国,Band Dream it’s my go到人物心里描写简直一绝)创造了许多令人喜爱的角色。
女朋友 > 喜欢二次元(连载 > 完结) >> 追星
23.08.27 to do
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
不同于恋爱番,催泪番,这样的分类。其实我更在意作品想表达的主题,作者想展现给读者什么。 无论是各种道理,还是就是某个环境,虚幻世界。
羁绊:对人的爱,爱情、亲情、友情。
| 番剧名 | 精神内核 | 评语 | 喜爱的角色 | 音乐 |
|---|---|---|---|---|
| Happy Sugar Life | 守护你是我的爱语 | 难以理解的爱的世界里,两位迷途少女相遇,救赎,领悟爱的蜜罐生活 | 砂糖、盐 | 金丝雀、ED、悲伤小提琴 |
我推的孩子(第一集)
Violet Garden
BanG Dream It's my go !!!!! 初羁绊(友情,百合,重女)的破碎和reunion
未来日记
家有女友、渣愿
百合类的成长:终将成为你,
我心危
命运石之门
RE0
寒蝉鸣泣之时
魔法少女小圆
复杂、紧张的鸿篇巨制。多非单一的精神内核可以概括。多为群像剧。
Fate Zero
钢炼
EVA
刀剑
四谎
CLANND
龙与虎
巨人
超炮
凉宫
鲁鲁修
轻音
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
TLB的介绍,请看
大体上是应用访问越随机, 数据量越大,pgw开销越大。
ISCA 2013 shows the pgw overhead in big memory servers.
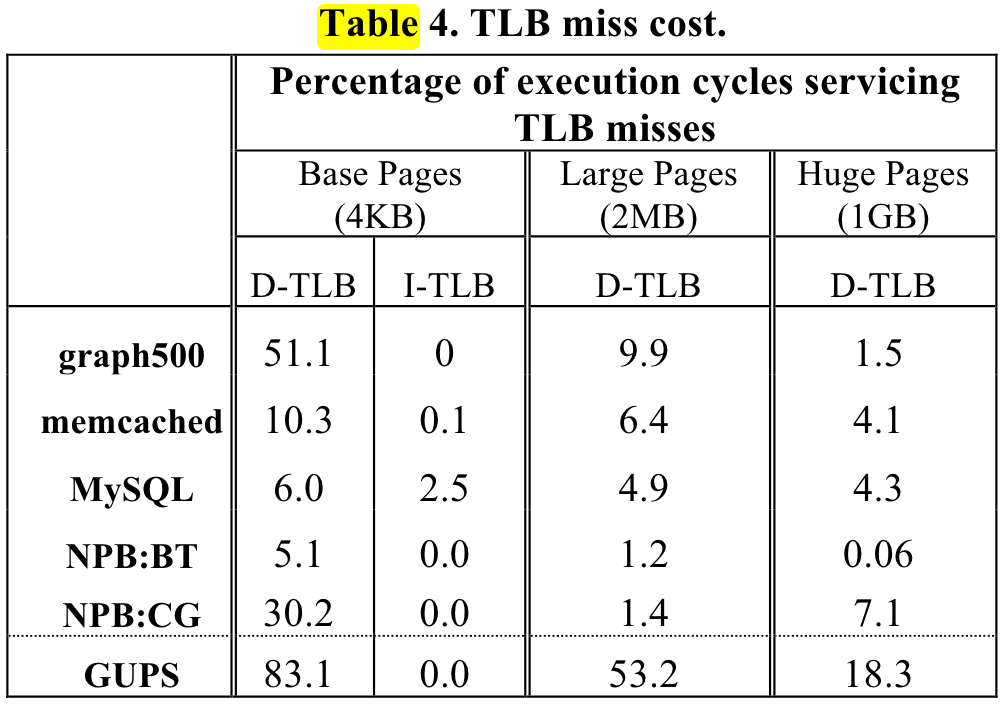
or ISCA 2020 Guvenilir 和 Patt - 2020 - Tailored Page Sizes.pdf
# shaojiemike @ snode6 in ~/github/hugoMinos on git:main x [11:17:05]
$ cpuid -1 -l 2
CPU:
0x63: data TLB: 2M/4M pages, 4-way, 32 entries
data TLB: 1G pages, 4-way, 4 entries
0x03: data TLB: 4K pages, 4-way, 64 entries
0x76: instruction TLB: 2M/4M pages, fully, 8 entries
0xff: cache data is in CPUID leaf 4
0xb5: instruction TLB: 4K, 8-way, 64 entries
0xf0: 64 byte prefetching
0xc3: L2 TLB: 4K/2M pages, 6-way, 1536 entries
# if above command turns out empty
cpuid -1 |grep TLB -A 10 -B 5
# will show sth like
L1 TLB/cache information: 2M/4M pages & L1 TLB (0x80000005/eax):
instruction # entries = 0x40 (64)
instruction associativity = 0xff (255)
data # entries = 0x40 (64)
data associativity = 0xff (255)
L1 TLB/cache information: 4K pages & L1 TLB (0x80000005/ebx):
instruction # entries = 0x40 (64)
instruction associativity = 0xff (255)
data # entries = 0x40 (64)
data associativity = 0xff (255)
L2 TLB/cache information: 2M/4M pages & L2 TLB (0x80000006/eax):
instruction # entries = 0x200 (512)
instruction associativity = 2-way (2)
data # entries = 0x800 (2048)
data associativity = 4-way (4)
L2 TLB/cache information: 4K pages & L2 TLB (0x80000006/ebx):
instruction # entries = 0x200 (512)
instruction associativity = 4-way (4)
data # entries = 0x800 (2048)
data associativity = 8-way (6)
default there is no hugopage(usually 4MB) to use.
$ cat /proc/meminfo | grep huge -i
AnonHugePages: 8192 kB
ShmemHugePages: 0 kB
FileHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
explained is here.
cat /sys/kernel/mm/transparent_hugepage/enabled but achieve this needs some details.echo 20 > /proc/sys/vm/nr_hugepages. And you need to write speacial C++ code to use the hugo page# using mmap system call to request huge page
mount -t hugetlbfs \
-o uid=<value>,gid=<value>,mode=<value>,pagesize=<value>,size=<value>,\
min_size=<value>,nr_inodes=<value> none /mnt/huge
But there is a blog using unmaintained tool hugeadm and iodlr library to do this.
sudo apt install libhugetlbfs-bin
sudo hugeadm --create-global-mounts
sudo hugeadm --pool-pages-min 2M:64
So meminfo is changed
$ cat /proc/meminfo | grep huge -i
AnonHugePages: 8192 kB
ShmemHugePages: 0 kB
FileHugePages: 0 kB
HugePages_Total: 64
HugePages_Free: 64
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 131072 kB
using iodlr library
Measurement tools from code
# shaojiemike @ snode6 in ~/github/PIA_huawei on git:main x [17:40:50]
$ ./investigation/pagewalk/tlbstat -c '/staff/shaojiemike/github/sniper_PIMProf/PIMProf/gapbs/sssp.inj -f /staff/shaojiemike/github/sniper_PIMProf/PIMProf/gapbs/benchmark/kron-20.wsg -n1'
command is /staff/shaojiemike/github/sniper_PIMProf/PIMProf/gapbs/sssp.inj -f /staff/shaojiemike/github/sniper_PIMProf/PIMProf/gapbs/benchmark/kron-20.wsg -n1
K_CYCLES K_INSTR IPC DTLB_WALKS ITLB_WALKS K_DTLBCYC K_ITLBCYC DTLB% ITLB%
324088 207256 0.64 733758 3276 18284 130 5.64 0.04
21169730 11658340 0.55 11802978 757866 316625 24243 1.50 0.11
平均单次开销(开始到稳定): dtlb miss read need 24~50 cycle ,itlb miss read need 40~27 cycle
案例的时间分布:
65000 100000超内存前,即使是全部在计算,都是0.24% 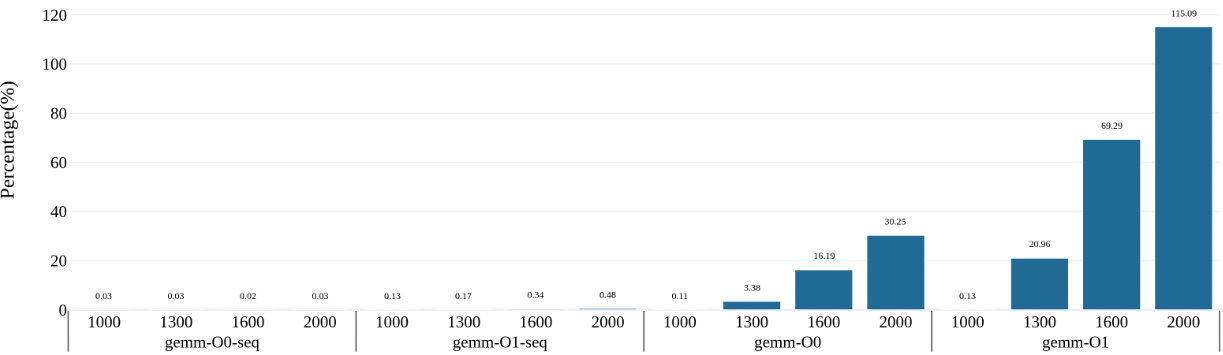
the gemm's core line is
for(int i=0; i<N; i++){
// ignore the overflow, do not influence the running time.
for(int j=0; j<N; j++){
for(int l=0; l<N; l++){
// gemm
// ans[i * N + j] += matrix1[i * N + l] * matrix2[l * N + j];
// for gemm sequantial
ans[i * N + j] += matrix1[i * N + l] * matrix2[j * N + l];
}
}
}
and real time breakdown is as followed. to do
manual code to test if tlb entries is run out
$ ./tlbstat -c '../../test/manual/bigJump.exe 1 10 100'
command is ../../test/manual/bigJump.exe 1 10 100
K_CYCLES K_INSTR IPC DTLB_WALKS ITLB_WALKS K_DTLBCYC K_ITLBCYC DTLB% ITLB%
2002404 773981 0.39 104304528 29137 2608079 684 130.25 0.03
$ perf stat -e mem_uops_retired.all_loads -e mem_uops_retired.all_stores -e mem_uops_retired.stlb_miss_loads -e mem_uops_retired.stlb_miss_stores ./bigJump.exe 1 10 500
Number read from command line: 1 10 (N,J should not big, [0,5] is best.)
result 0
Performance counter stats for './bigJump.exe 1 10 500':
10736645 mem_uops_retired.all_loads
532100339 mem_uops_retired.all_stores
57715 mem_uops_retired.stlb_miss_loads
471629056 mem_uops_retired.stlb_miss_stores
In this case, tlb miss rate up to 47/53 = 88.6%
using big hash table
Any algorithm that does random accesses into a large memory region will likely suffer from TLB misses. Examples are plenty: binary search in a big array, large hash tables, histogram-like algorithms, etc.
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
秋招面试时遇到高铁柱前辈。问了相关的问题(对AI专业的人可能是基础知识)

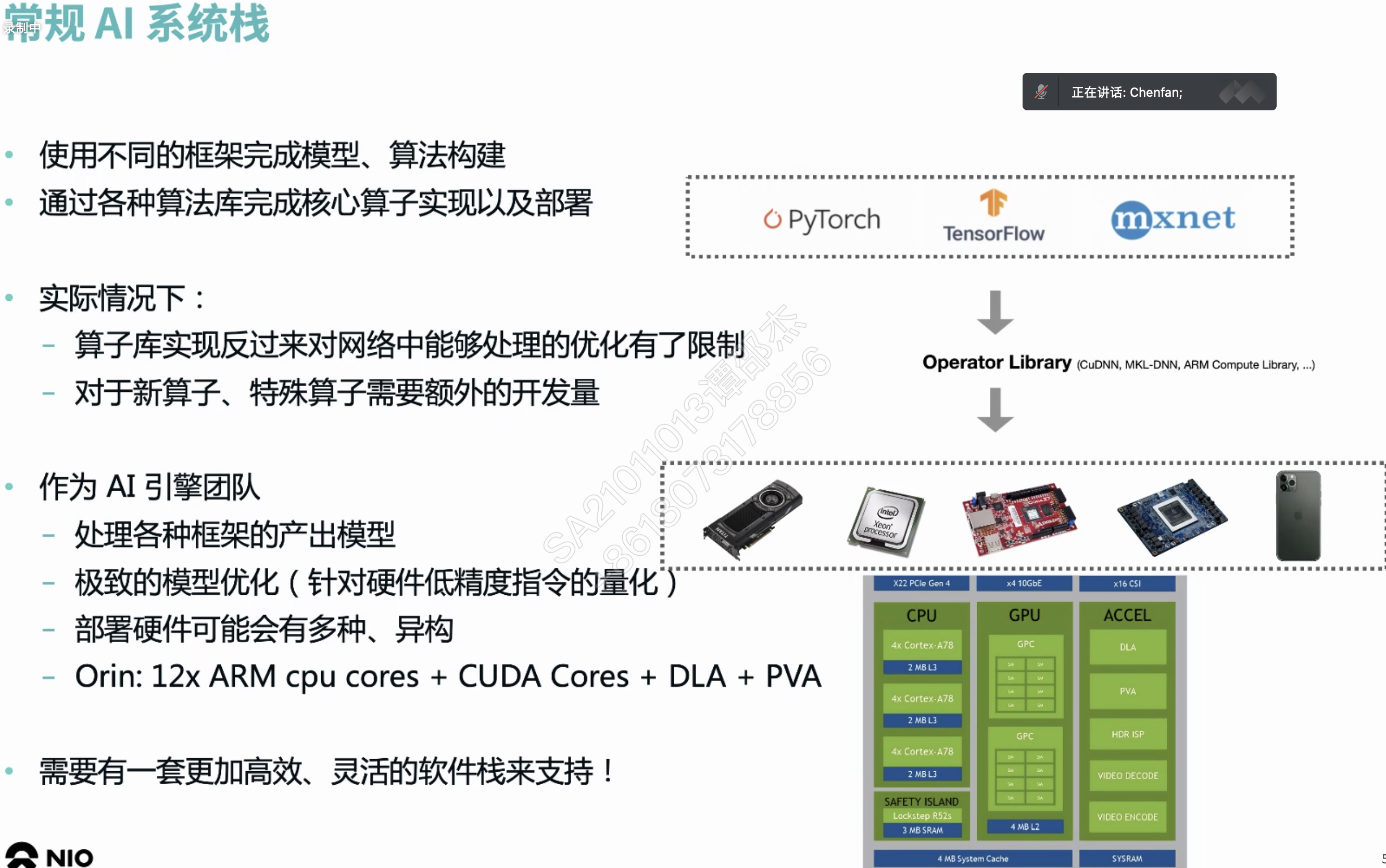
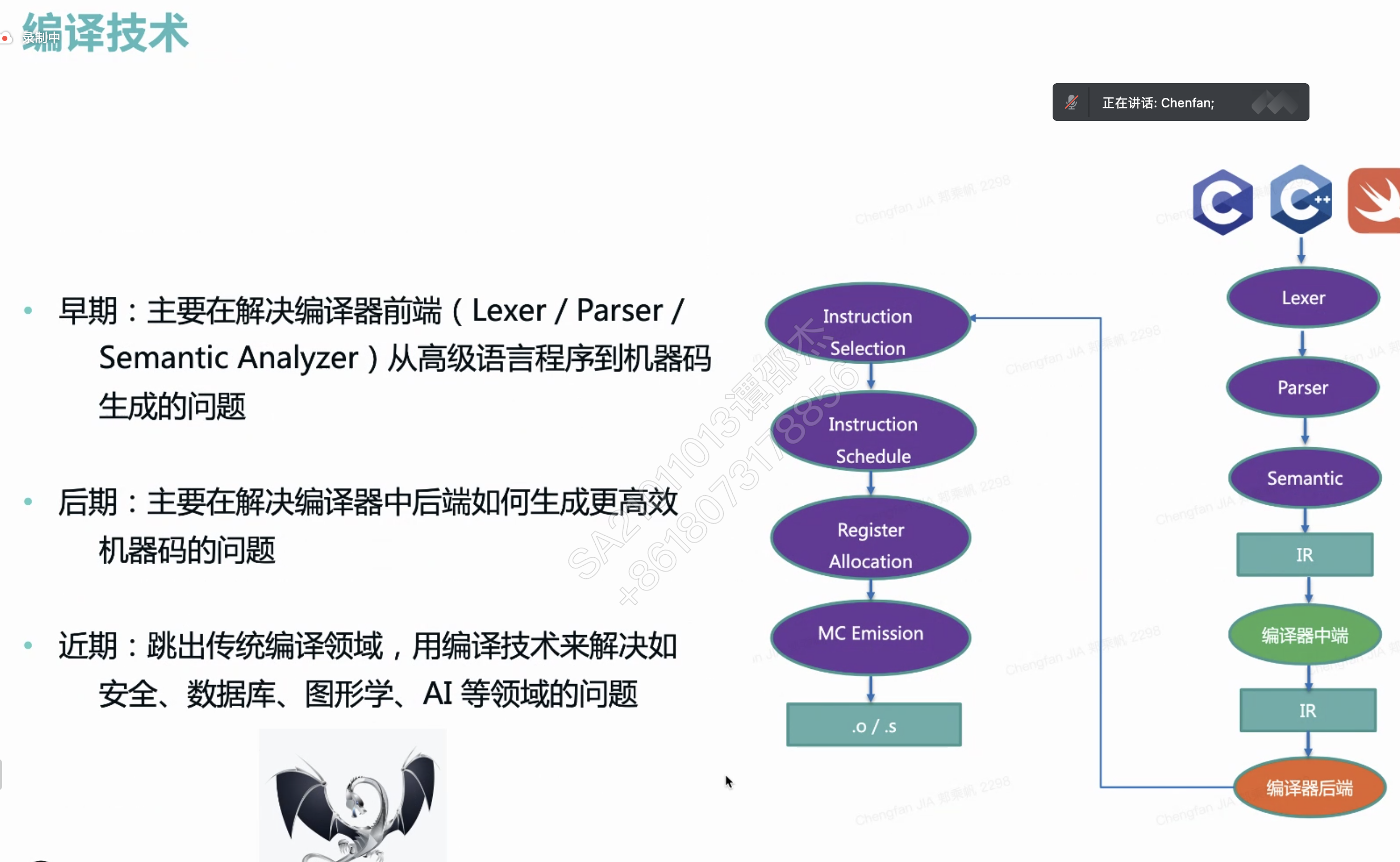
数字信号处理器 (Digital signal processor)
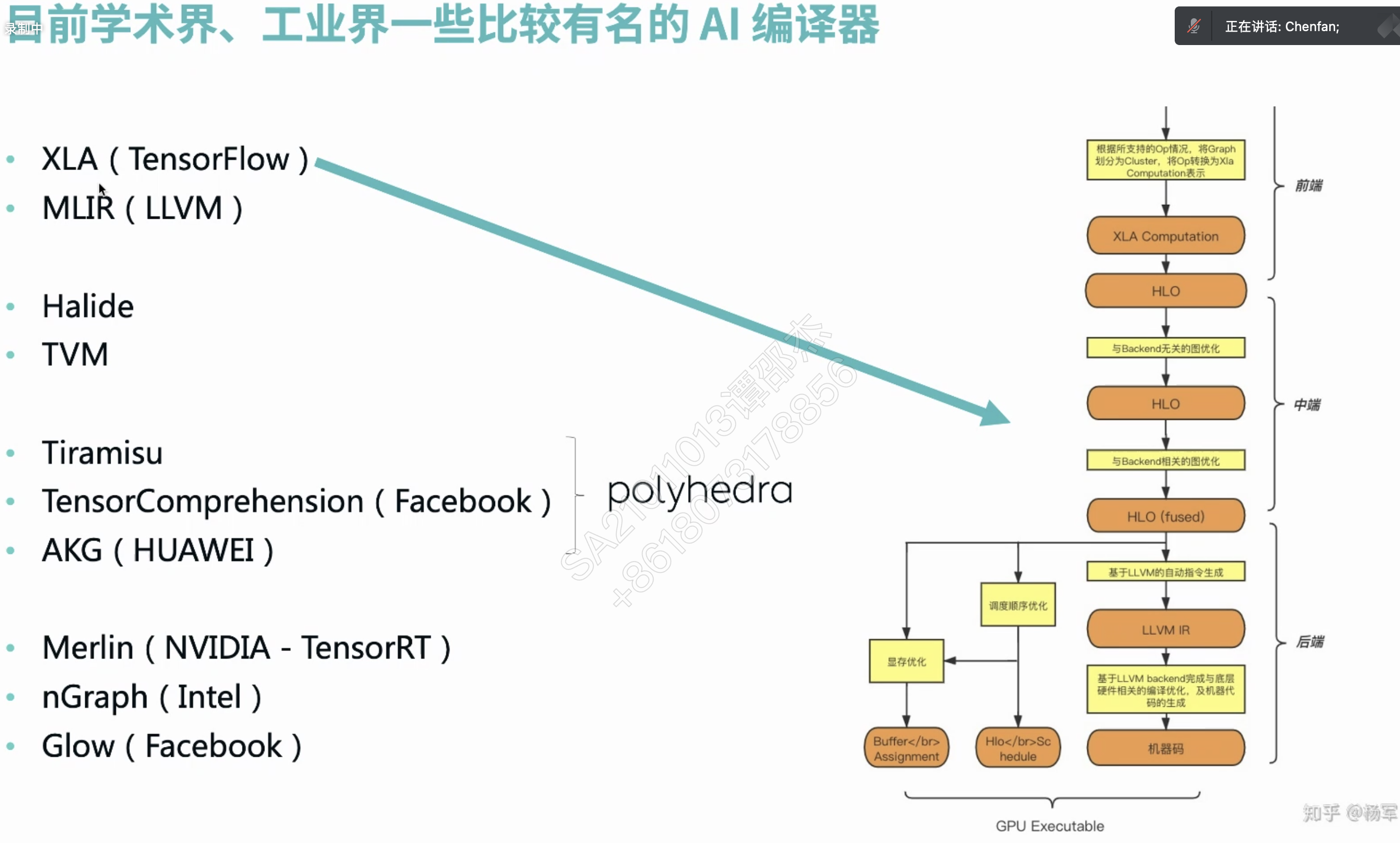
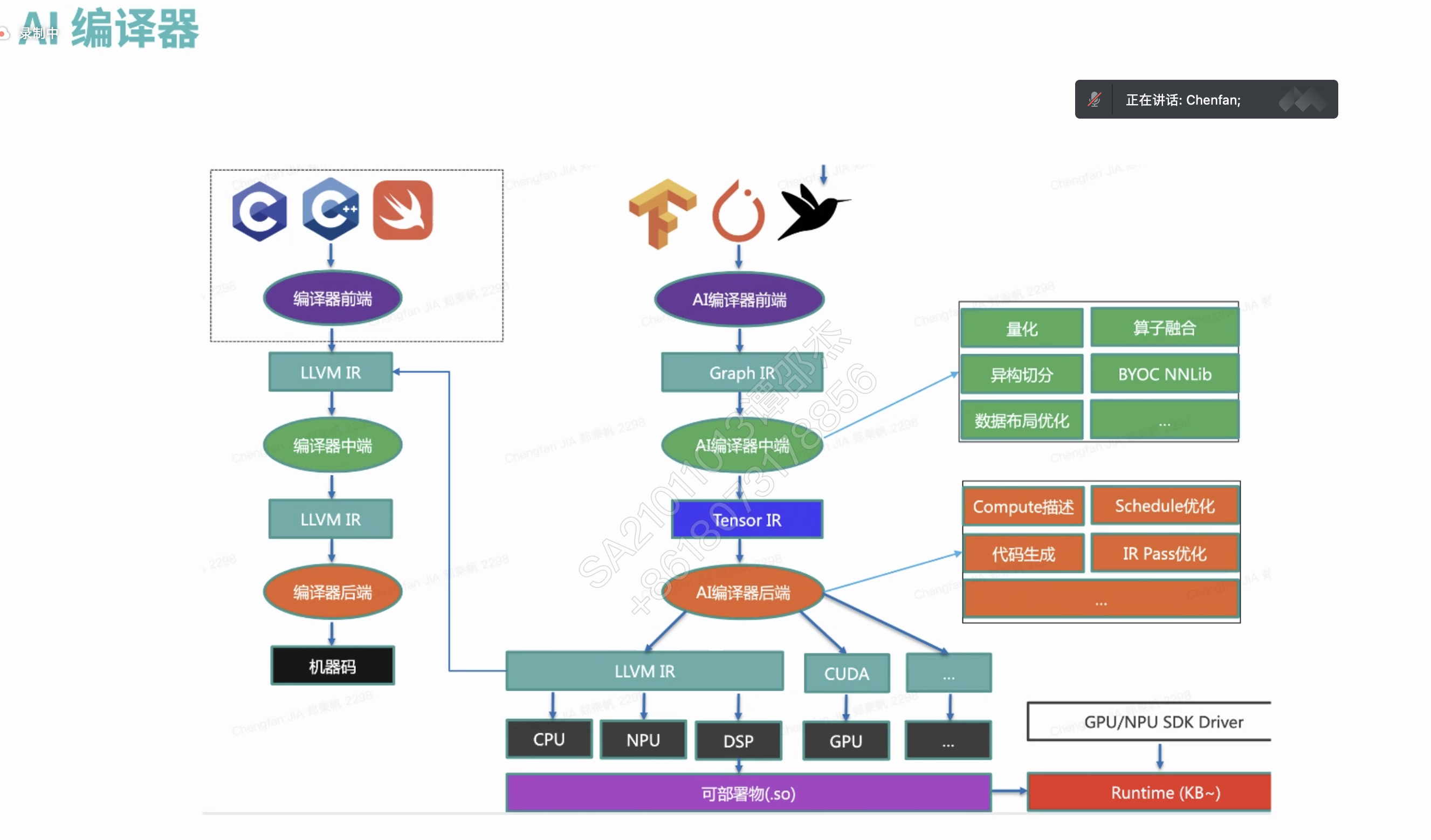
HLO 简单理解为编译器 IR。
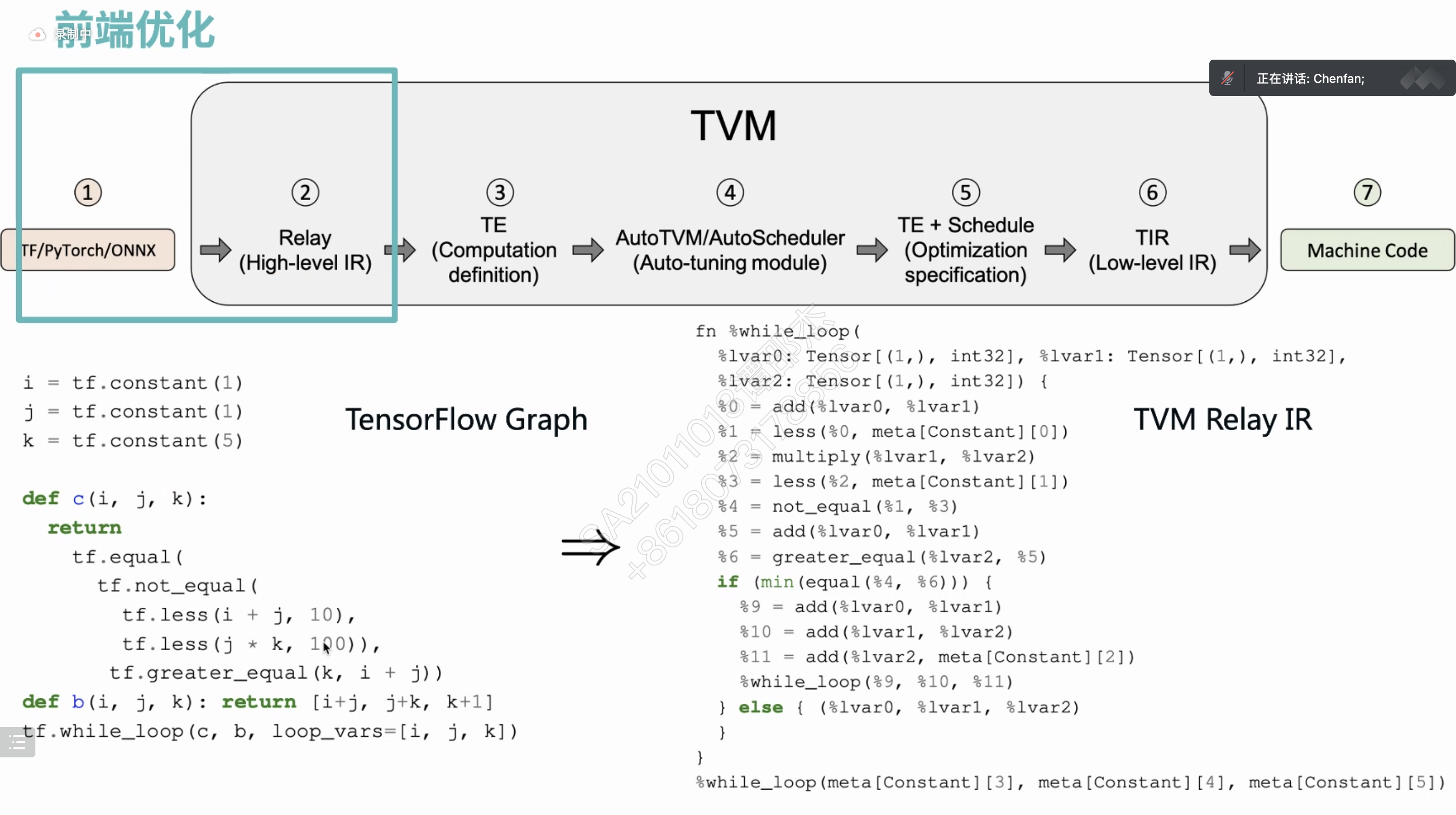
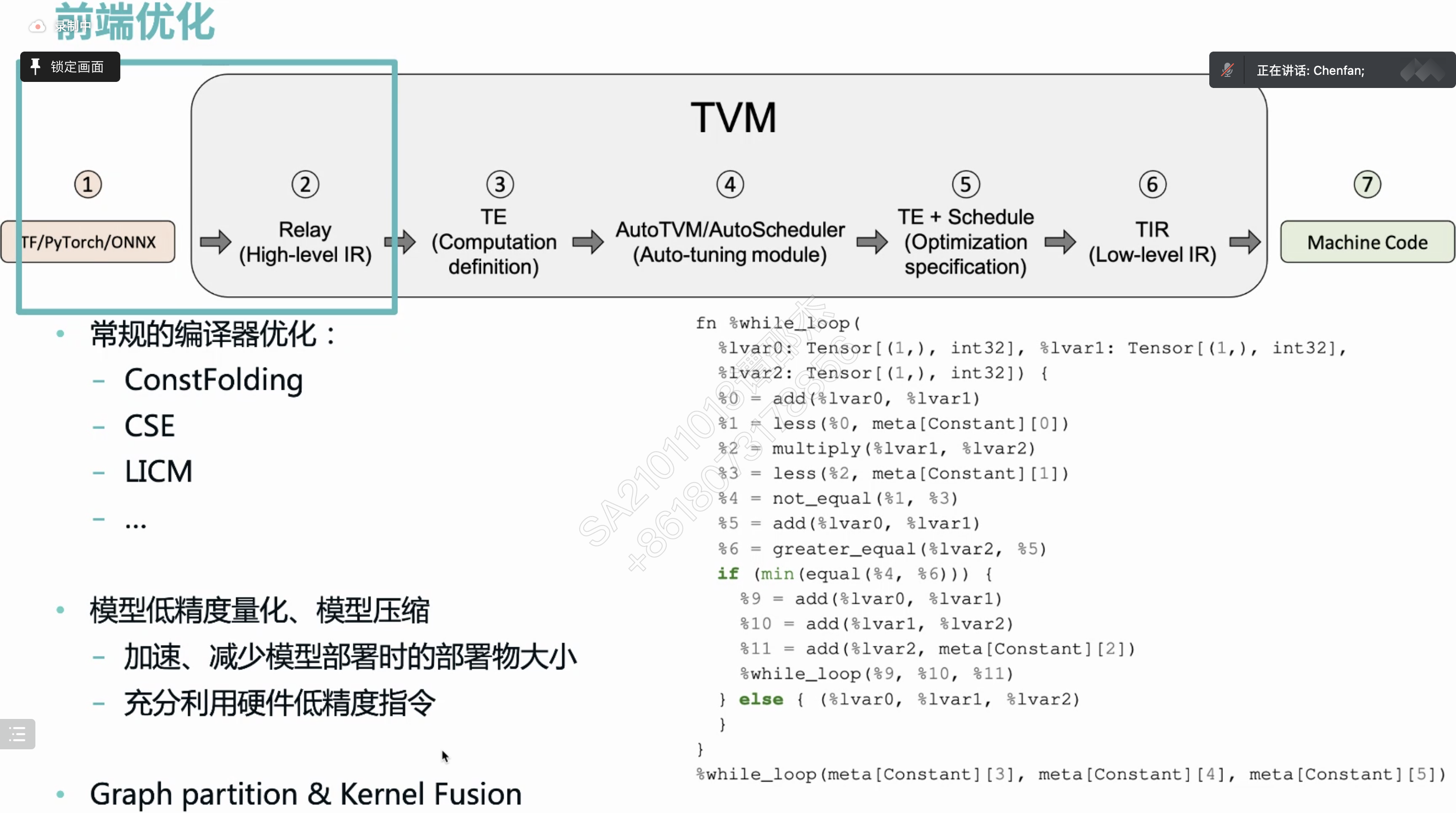
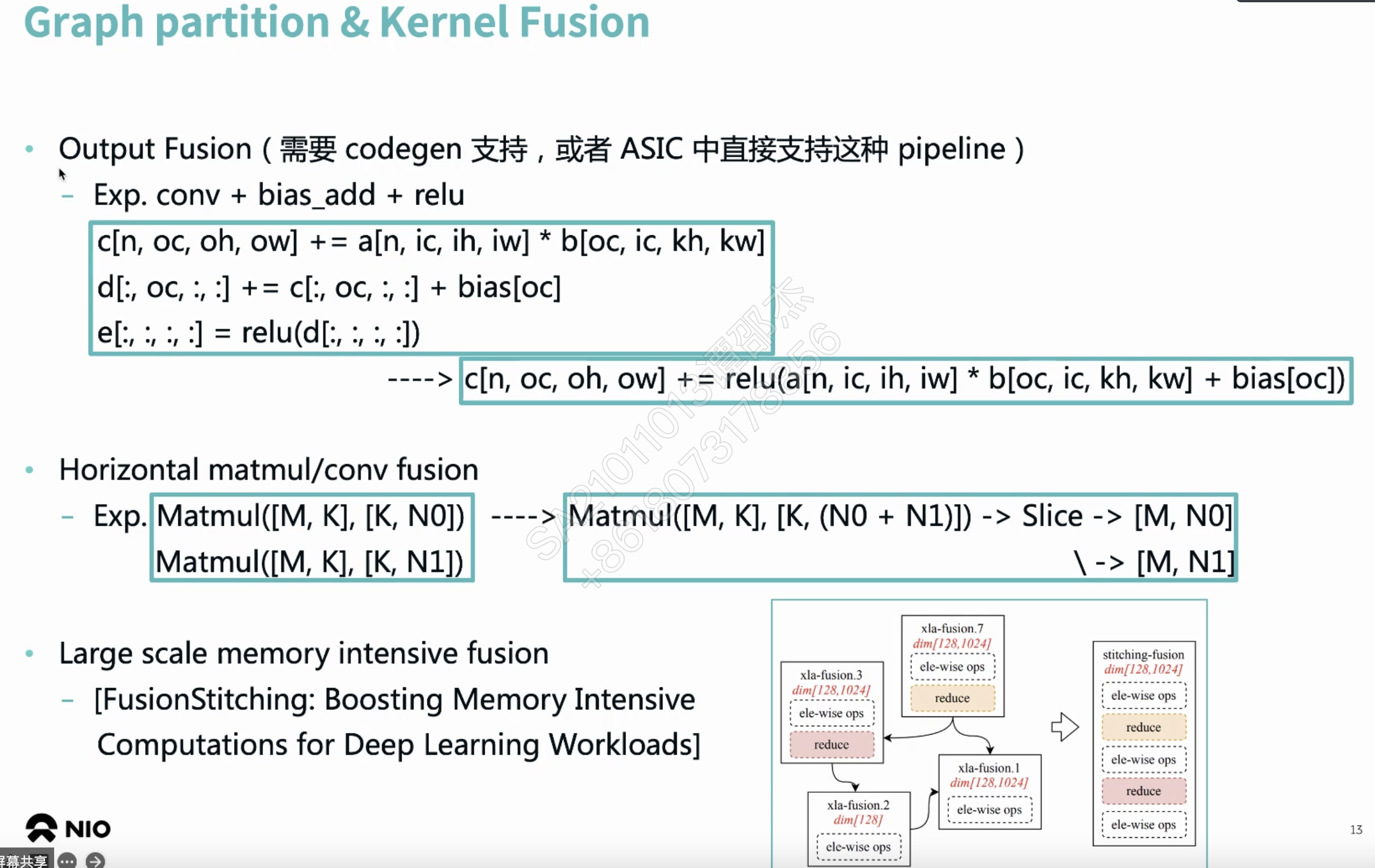
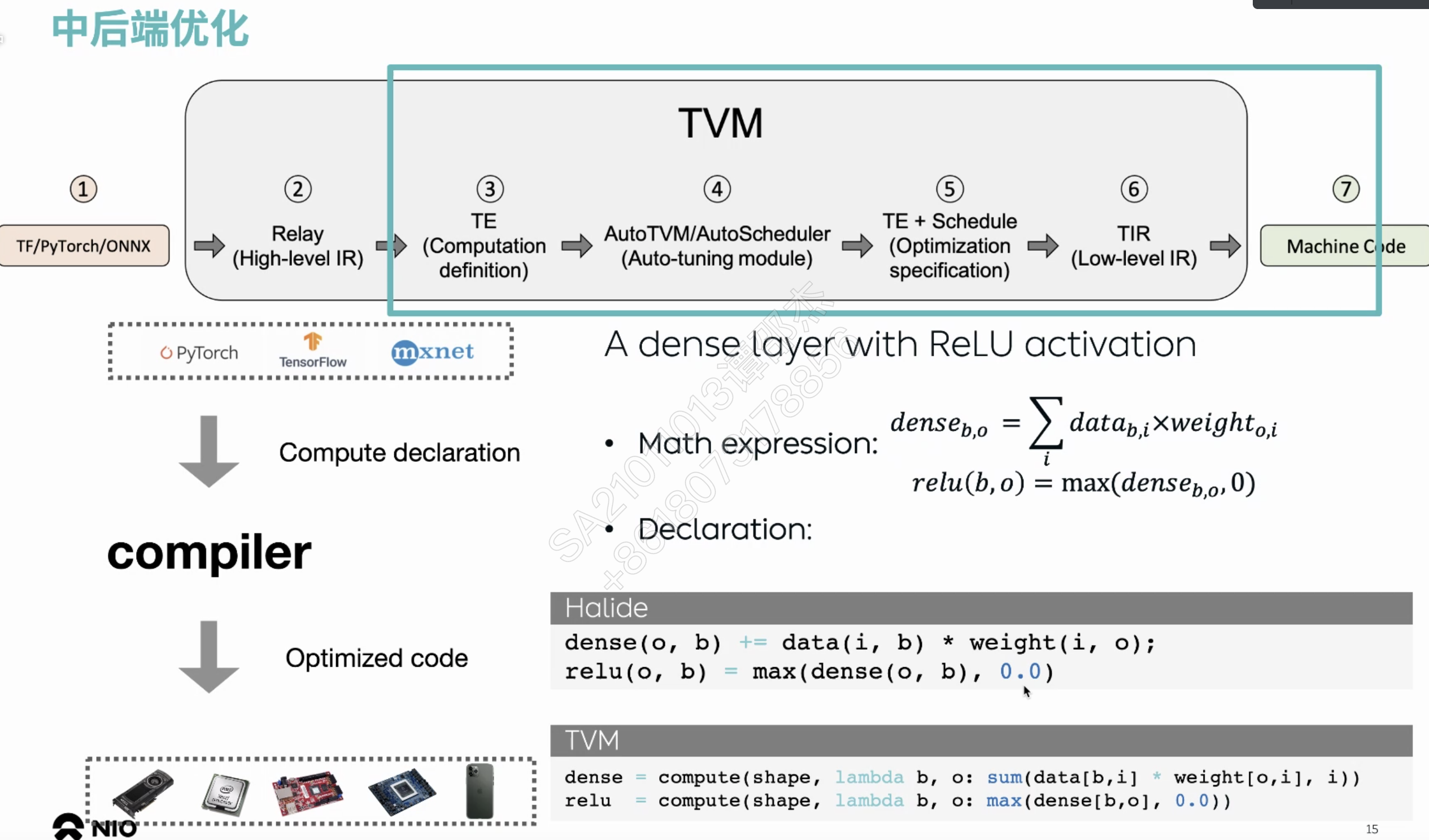
把中间算子库替换成编译器?

暂时不好支持张量
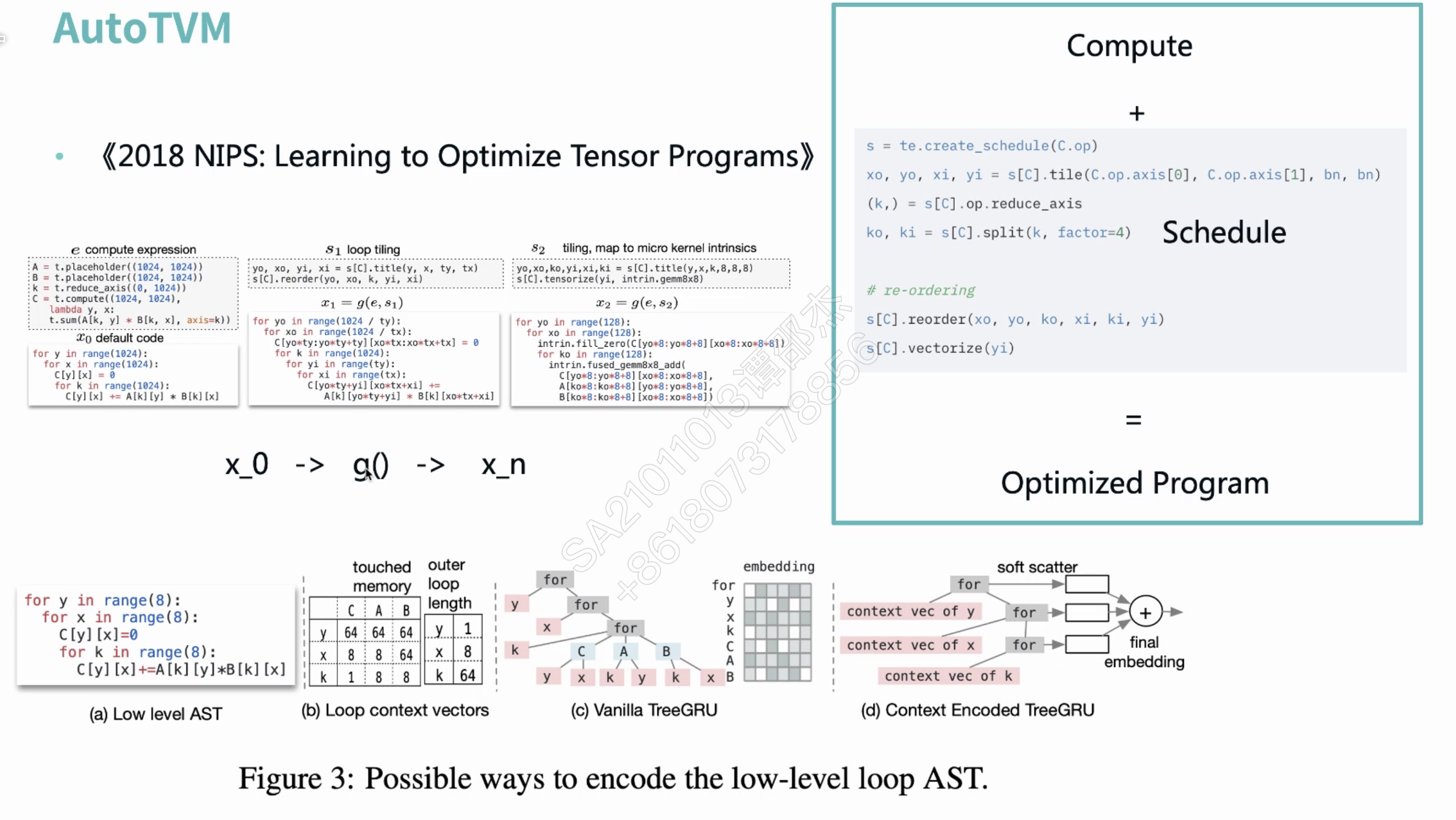
AI自动调整变化来调优
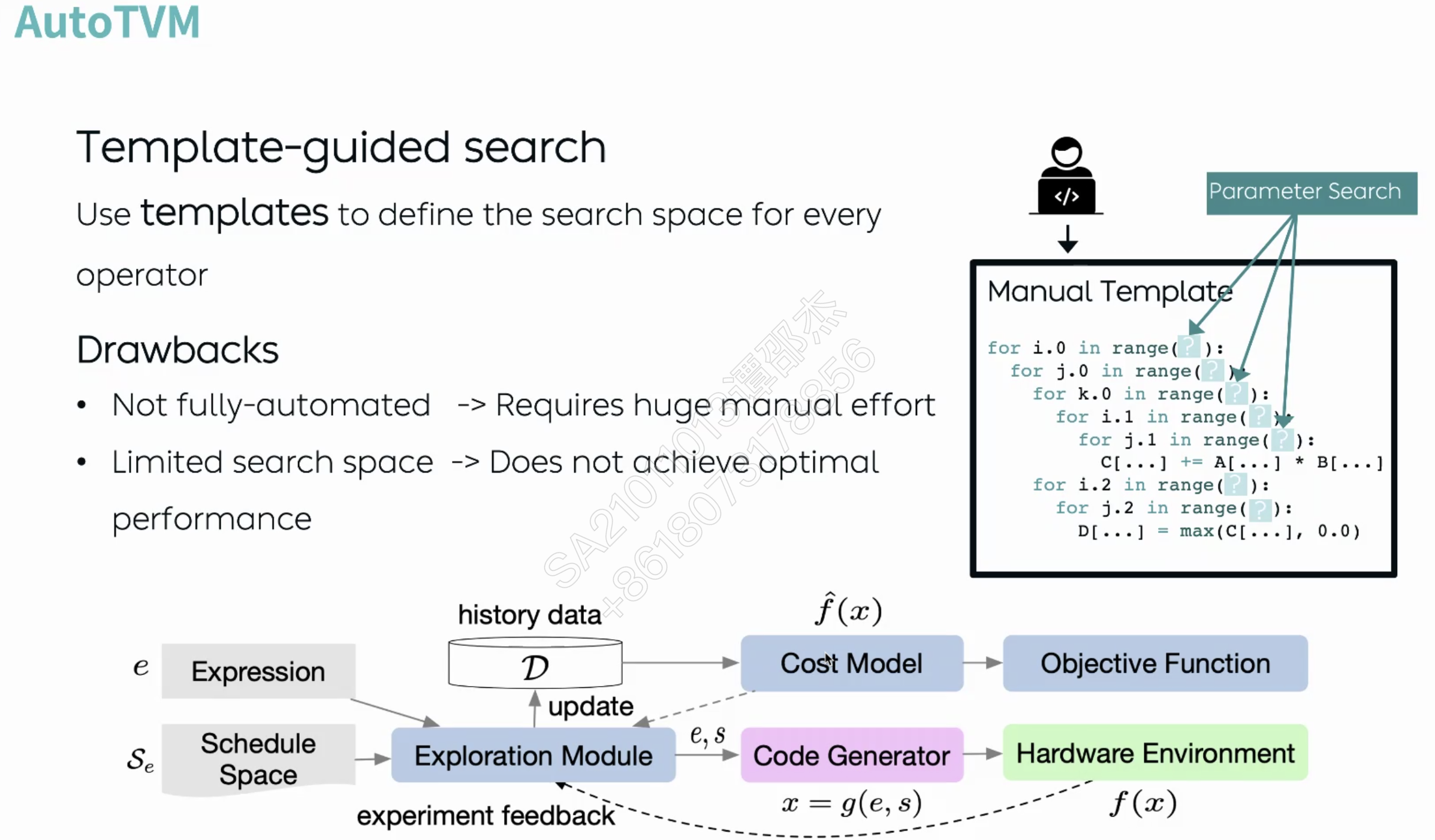
自动调参。缺点:

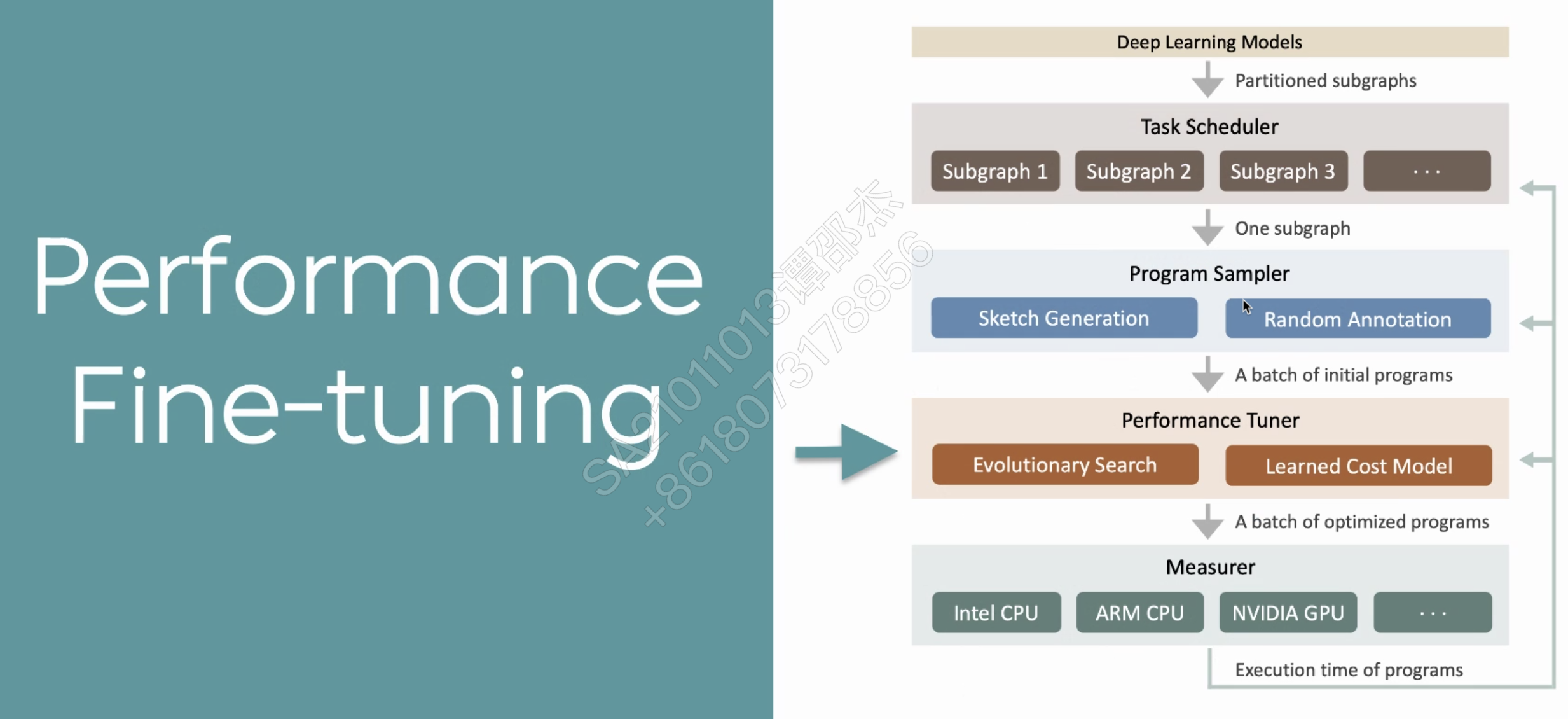
随机各级循环应用优化策略(并行,循环展开,向量化

介绍了Ansor效果很好
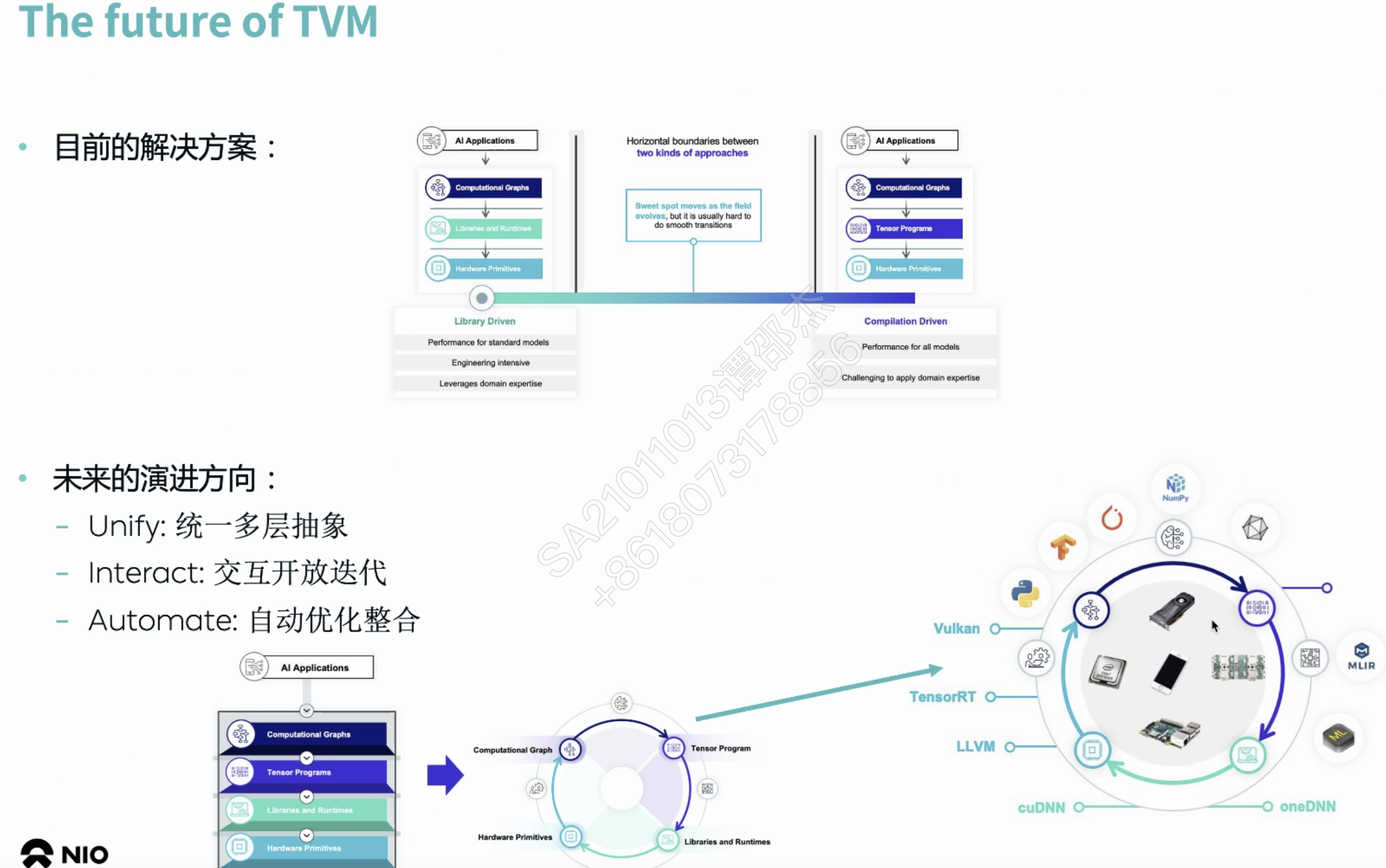
暂无
暂无
无