Diffusion LLM Post-Training
导言
dLLM 的核心变化不是把 LLM 外面套一层 diffusion 名字,而是把语言生成从 left-to-right next-token prediction 改成 masked denoising over a token canvas。这会连带改变 SFT 的数据变换、loss 位置、attention mask、采样器,以及 RL 中最敏感的 logprob 对齐方式。
本文基于 2026-06-25 对 inclusionAI/dFactory、ZHZisZZ/dllm 和 ByteDance-Seed/VeOmni 的源码调研,回答三个工程问题:dLLM 相对传统 LLM 原理有何不同,SFT/RL 代码流程如何变化,以及如果迁移到传统 SFT 仓 VeOmni,大概需要补哪些模块。
结论先行¶
- 原理差异:传统 LLM 学的是 \(p(x_i \mid x_{<i})\),通过 causal mask 从左到右生成;dLLM 学的是在随机 mask 后从 \(x_t\) 恢复 \(x_0\),通常可以用双向上下文,并在推理时多步迭代去噪。
- SFT 差异:传统 SFT 的主线是 chat template、shift labels、prompt loss mask;dLLM SFT 还要采样噪声强度、把 response token 随机替换为
[MASK]、只在被 mask 位置计算恢复 loss。 - RL 差异:reward 仍然评估最终文本,但 policy logprob 不再天然来自自回归生成轨迹。
diffu-GRPO需要用同一个 mask seed 对 old/ref/current 重新计算 completion token 的 diffusion logprob,否则 ratio 会因为随机 mask 漂移。 - 迁移到 VeOmni:SFT 可以参考 dFactory,属于中等工作量;RL 不是把 GRPO trainer 参数改一下,核心工作量在 sampler、old/ref/current logprob 对齐、分布式 rollout 和 reference policy 管理。
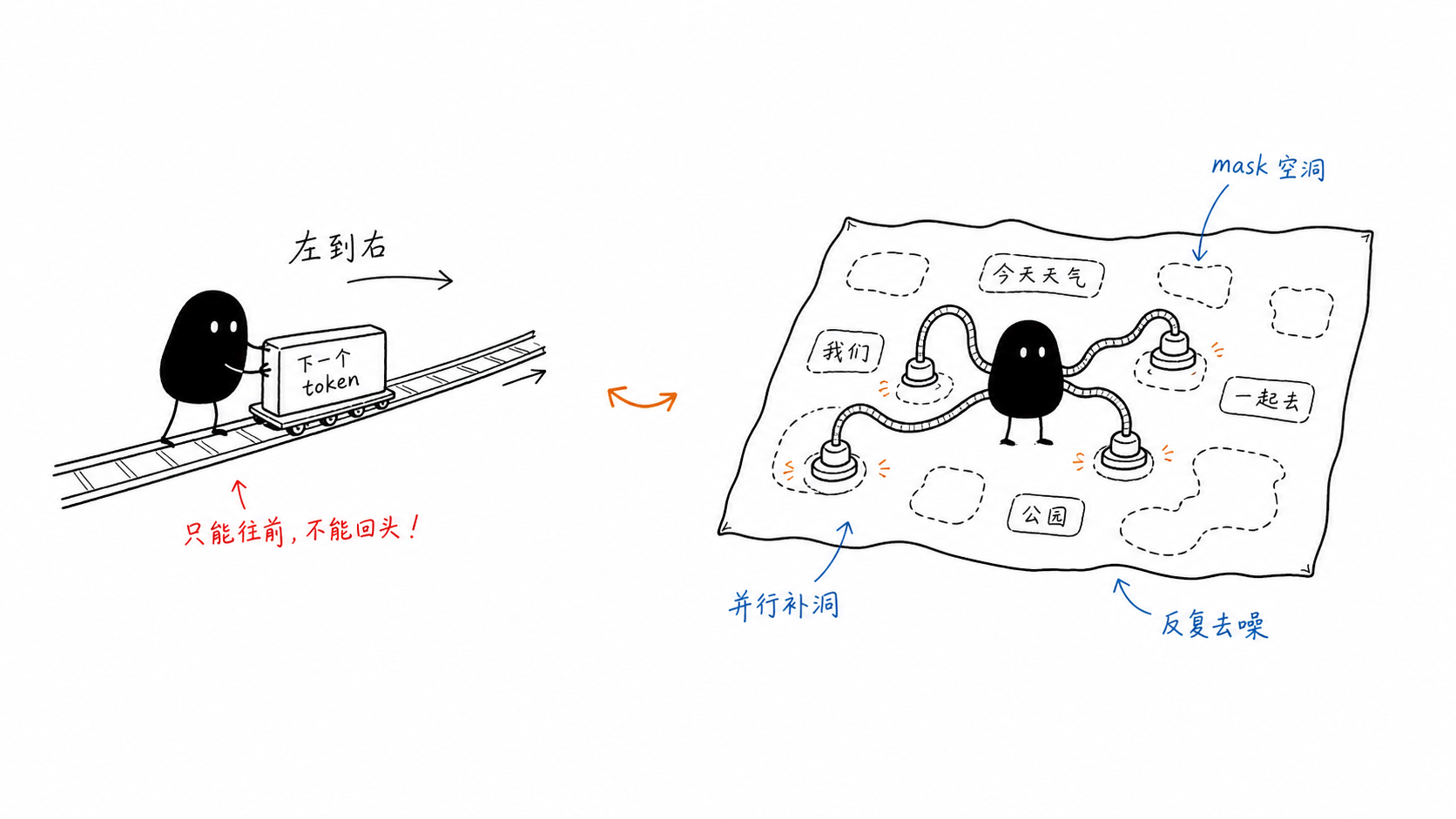
原理差异¶
自回归 LLM¶
传统 LLM 的训练目标是 next-token prediction:
这带来几个稳定的工程假设:
- Causal attention:当前位置只能看左侧上下文。
- Teacher forcing:训练时输入完整序列,但 loss 对齐到下一个 token。
- 生成路径明确:推理时一次提交一个 token,token logprob 自然对应每个动作。
- 长度增长式生成:序列从 prompt 右侧不断变长。
这些假设让 SFT 和 RL 代码很直观:SFT 做 labels 右移,RL 做 rollout 后把生成 token 的 logprob 拿回来。
dLLM¶
dLLM 更接近 masked diffusion language modeling。训练时先从干净文本 \(x_0\) 构造带噪文本 \(x_t\),通常是把一部分 token 替换成 mask token,然后让模型预测原始 token。ZHZisZZ/dllm 的 MDLMTrainer 在 compute_loss 中采样 timestep,计算 mask 概率,对 labels != -100 的 token 随机 mask,再对原始 input_ids 做 cross entropy。8
直观理解是:
- 输入不是前缀,而是带洞的整句。
- 目标不是下一个 token,而是恢复被 mask 的 token。
- 推理不是单步追加,而是在固定或半固定 canvas 上迭代提交 token。
- confidence、remasking、block_size、steps 会成为推理策略的一部分。
这解释了为什么 dLLM 可以天然支持 infilling、parallel decoding、局部修复等形态,但也解释了为什么训练和 RL 会变复杂:策略不再是简单的左到右 token 链。
不要把 dLLM 简化成 BERT
BERT 也做 masked language modeling,但通常不是一个面向长文本生成和多步去噪采样的生成模型。dLLM 的关键在于 训练目标、采样器、长度 canvas、反复去噪和后训练算法 共同形成生成范式,而不只是“把 token 随机 mask 掉”。
Block Diffusion¶
Block diffusion 是介于 autoregressive 和 full masked diffusion 之间的折中。dllm 的 BD3LMTrainer 会把 noised input 和 clean input 拼成 x_t ⊕ x_0,再用专门的 block attention mask 约束当前 block、历史 clean block 和 block 内 denoising 的可见关系。9 dFactory 的 LLaDA2 SFT 脚本也实现了同类 block diffusion mask,并在 forward 前把 noisy_input_ids 和 clean_input_ids 拼接。6
工程上,block diffusion 的含义是:
- 可以保留一部分块级自回归结构,降低完全并行去噪的不稳定性。
- attention mask 不再是普通 2D padding mask 或 causal mask,而可能是
2L x 2L的特殊 mask。 - 训练脚本要明确区分 noisy half 和 clean half,只对 noisy half 的 logits 计算 loss。
SFT 流程差异¶
传统 SFT¶
传统文本 SFT 通常是:
- 应用 chat template:把 messages 展开成模型训练序列。
- 构造 labels:prompt 部分置为
-100,response 部分保留真实 token。 - 右移预测:模型在位置 \(i\) 预测 \(i+1\) 的 token。
- causal loss:只在 response 有效 token 上算 cross entropy。
VeOmni 当前的 TextTrainer 就是这种思路:conversation 数据由 process_conversation_example 通过 chat template 编码;BaseTrainer.forward_backward_step 把 batch 直接喂给模型,再从 outputs.loss 汇总 loss。1314
dLLM SFT¶
dLLM SFT 在传统 SFT 之外多了一个 forward noising 过程:
input_ids = chat_template(messages)
labels = input_ids.clone()
labels[:prompt_length] = -100
maskable_mask = positions >= prompt_length
noisy_input_ids = mask(input_ids, maskable_mask, noise_range)
loss_mask = noisy_input_ids == mask_token_id
labels[~loss_mask] = -100
dFactory 的 process_mdm_sft_example 正是这么做的:它保留 clean input_ids,生成 noisy_input_ids,并且只让被 mask 的 response token 参与 loss。5 这和传统 SFT 的核心差异在于 labels 不再等于“所有 response token 都算 loss”,而是“本次随机噪声真正遮住的位置才算 loss”。
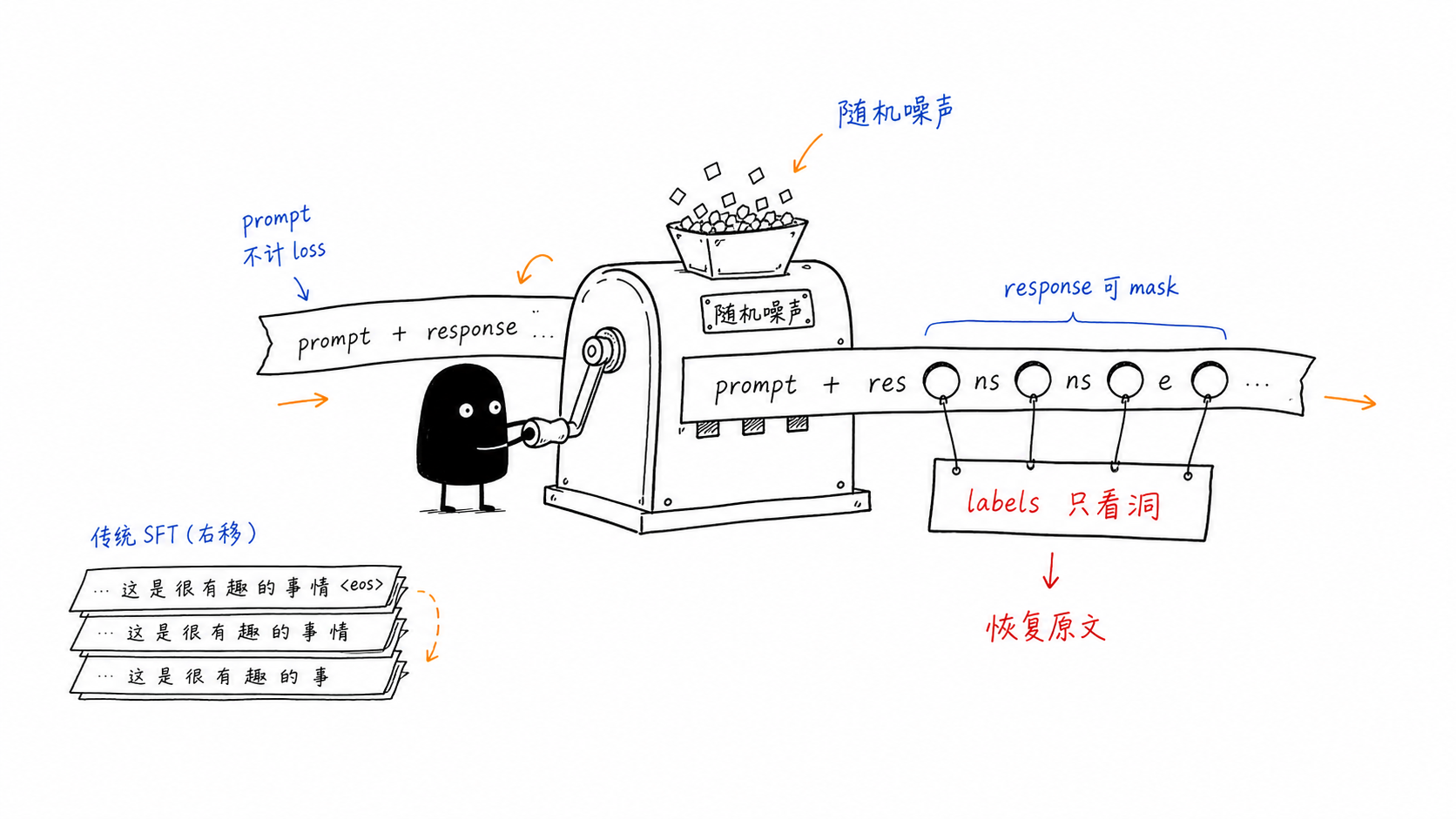
Loss 位置¶
实际代码里会出现两种选择:
- Same-token labels:
logits[:, i]直接预测当前位置原 token。dFactory 用same_token_labels开关控制。6 - Shifted labels:为了兼容某些 causal LM 头或模型实现,仍然把 logits 和 labels 做一位 shift。
对 dLLM 来说,same-token 更符合直觉:模型看到某个位置是 mask,就在这个位置输出原 token 分布。Shifted labels 更多是工程兼容问题,而不是 diffusion 目标本身的必要条件。
迁移时优先做最小闭环
如果目标是先在 VeOmni 里跑通 dLLM SFT,建议先做 full-attention MDLM,同步验证 noisy_input_ids -> logits -> masked CE 的正确性。Block diffusion、sequence parallel、dynamic batch 和 NPU 特化可以后置,否则一次性变量太多。
RL 流程差异¶
传统 GRPO¶
自回归 GRPO 的关键对象比较自然:
- 对同一个 prompt 采样 \(K\) 个 completion。
- 用 reward function 给每个 completion 打分。
- 计算组内相对优势。
- 用 old policy、current policy、reference policy 对同一串生成 token 计算 logprob。
- 用 ratio、clip 和 KL 更新 actor。
这里的 token logprob 来自生成动作本身:第 \(i\) 个 token 是在前缀 \(x_{<i}\) 下采出来的。
Diffu-GRPO¶
dLLM 的 rollout 是 iterative denoising。dllm 的 DiffuGRPOTrainer 保留了 TRL GRPO 的奖励、优势和 KL 框架,但重写了四个关键点:生成、per-token logprob、loss 注入和输入 shuffle。10
最关键的是 _get_per_token_logps:
- 对 prompt+completion 做 diffusion forward process。
- prompt token 以
p_mask_prompt概率被 mask。 - completion token 被视为要评估的目标区域。
- 模型对 noised input 做一次 forward。
- 对 completion targets 计算 cross entropy,取负数作为 per-token logprob。10
这意味着 dLLM RL 不是“从采样器里直接拿每一步动作概率”那么简单。它更像是:先生成一个最终答案,再用一个固定的 noising 视角去问模型“你是否能从这些洞恢复出这个答案”。
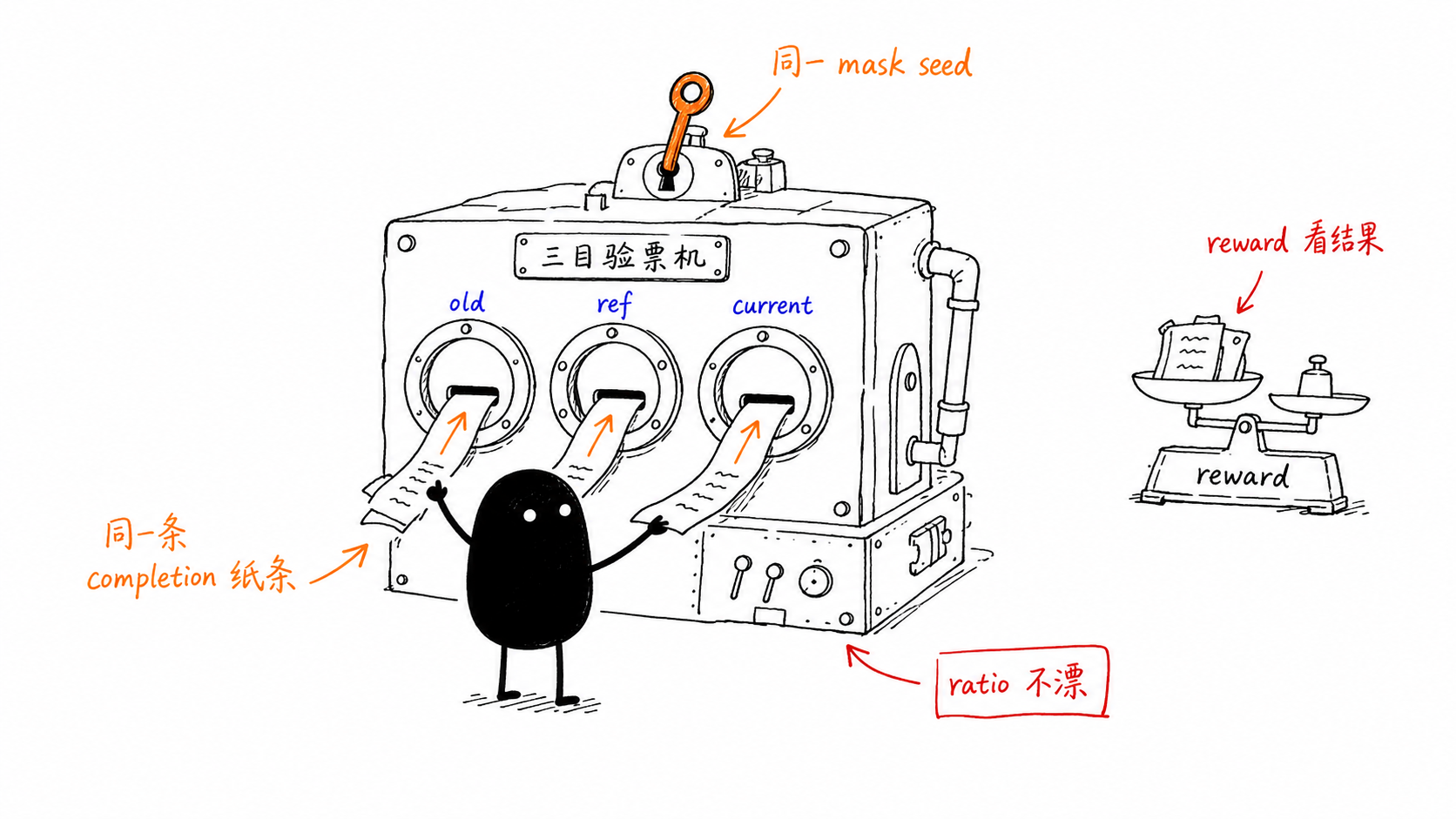
为什么同一个 mask seed 很重要¶
GRPO 的 ratio 对 logprob 差异非常敏感。对 dLLM,如果 old/ref/current 每次重新随机 mask 不同位置,那么三者并没有在比较同一个事件:
- old policy 可能在评估第 3、5、9 个洞。
- current policy 可能在评估第 2、5、10 个洞。
- reference policy 又可能看到另一组洞。
这会让 ratio 混入 forward-process 噪声,而不只是 policy 变化。DiffuGRPOTrainer 因此为每个 inner iteration 生成 mask seed,并把 old/ref logps 预先按 iteration 堆起来;训练时按 _diffu_iter_idx 取对应 seed,保证 old/ref/current 对齐。11
RL 迁移的核心不是 reward
对 dLLM 来说,reward function 可以和传统 LLM 共享,例如 GSM8K correctness、format reward、code test reward。真正麻烦的是 policy probability 的定义和复现。如果 logprob 事件不一致,reward 再准确也会训练出不稳定的 ratio。
迁移到 VeOmni 的工作量¶
当前 VeOmni 能直接复用的部分¶
VeOmni 的优势在训练底座,而不是 dLLM 目标函数本身:
- 模型加载和分布式:已有 FSDP/FSDP2、TP、EP、Ulysses、checkpoint、wandb、profiler 等基础设施。
- 文本 SFT 主线:
TextTrainer已经支持 conversation 数据、chat template、tokenizer、dataloader 和标准训练 loop。13 - 可扩展 hook:
BaseTrainer明确允许子类覆盖forward_backward_step、postforward、train_step等方法。14 - RL 底座:
BaseRLTrainer已经把 RL 的 pack/SP slice 移到 training loop 内,并在 postforward 里汇总 sample-wise logits,但当前逻辑仍是 causal shift CE。15
需要注意,VeOmni 主线里的 veomni/data/diffusion/ 主要服务 DiT 或图像/视频 diffusion 数据,不等价于文本 dLLM 的 masked token diffusion。
SFT 迁移清单¶
如果目标是把 dFactory 的 LLaDA2 SFT 合入 VeOmni 风格仓库,建议拆成六块:
- 模型注册
- 把 LLaDA2 modeling/config/parallel plan 接入 VeOmni model registry。
- 明确
mask_token_id,不要在 trainer 里硬编码156895。 -
如果用 MoE merged-expert 训练,还要保留 merge/split 权重转换流程。
-
参数结构
- 在
DataArguments或自定义LLaDA2DataArguments中加入noise_range_low、noise_range_high、mask_token_id。 - 在
TrainingArguments中加入block_diffusion_mode、block_size、same_token_labels。 -
VeOmni 当前
DataArguments.data_type虽然包含diffusion,但__post_init__对diffusion没有默认text_keys分支,data_transform.py也没有注册文本 masked diffusion transform;直接使用还不能得到 dLLM 训练样本。16 -
DataTransform
- 新增
mdm_conversation或diffusion_conversationtransform。 - 输出
input_ids、noisy_input_ids、labels、attention_mask、position_ids。 -
prompt 置
-100,未被 mask 的 response 也置-100。 -
Collator
- 给
noisy_input_ids加入 collate 规则,padding、SP slice 和 dynamic batch 要和input_ids对齐。 -
统计 token 数时优先用
labels != -100的 effective token,否则 prompt-heavy batch 会误导动态 batching。 -
Trainer
- full-attention MDLM:override
forward_backward_step,把noisy_input_ids作为input_idsforward,计算 masked CE。 - block diffusion:在 forward 前拼接
[noisy_input_ids, clean_input_ids],构造2L x 2Lattention mask 和重复 position ids,只取 noisy half logits。 -
loss 不应依赖 HF causal LM 内置
outputs.loss,因为它默认是 next-token loss。 -
测试
- DataTransform 单测:prompt 不参与 loss,mask ratio 在范围内,被 mask 的 label 保留原 token。
- Tiny forward 单测:same-token 和 shifted 两种 loss 与手算一致。
- Block mask 单测:block diagonal、offset block causal、block causal 三类关系正确。
- 分布式冒烟:FSDP2、SP、dynamic batch、checkpoint save/load 至少各跑一个小样本。
工作量估计¶
| 目标 | 估计工作量 | 主要风险 |
|---|---|---|
| Full-attention MDLM SFT 最小闭环 | 3-5 人日 | 模型能否直接被 VeOmni 加载,mask_token_id 和 labels 对齐 |
| Block diffusion SFT | 1-2 周 | 2L x 2L attention mask 与 SDPA/FlexAttention/SP/FSDP2 的兼容 |
| LLaDA2 MoE 生产级训练 | 2-4 周 | merged-expert 权重、EP/FSDP2、保存 HF 权重、NPU/GPU kernel 差异 |
| Diffu-GRPO 原型 | 2-3 周 | sampler 和 logprob 对齐,old/ref/current seed 复现 |
| VeOmni 原生 dLLM RL | 3-6 周 | 分布式 rollout、reference model、PEFT、reward、buffer、no-shuffle 机制 |
这个估计假设已有模型权重、tokenizer 和基础数据集可用。如果还要适配新模型结构或新硬件后端,工作量会继续上浮。
后续问题¶
算法问题¶
- dLLM 的 token logprob 是否足够等价于策略概率:diffu-GRPO 用 forward masking 后的恢复概率作为 per-token logprob,这是一种可训练 surrogate,但它和完整 denoising trajectory probability 不是同一个对象。
- mask schedule 如何影响 RL 稳定性:
p_mask_prompt、completion always-mask、steps、block_size、remasking 都会改变梯度信号。 - reward 稀疏时如何探索:dLLM 的并行修复能力可能有利于 infilling-guided exploration,但也可能让高分 completion 的生成路径更难归因。
- same-token 与 shifted loss 的取舍:same-token 更贴合 masked denoising,shifted 更容易兼容 causal LM 头和已有 loss kernel。
- block diffusion 的最优粒度:block 越小越接近自回归,越大越接近 full diffusion,训练稳定性和推理效率需要实测。
工程问题¶
- 是否要把 dLLM 做成独立 trainer:SFT 阶段可用
DiffusionTextTrainer,避免污染普通TextTrainer。 - 是否复用 TRL 的 DiffuGRPO:原型可复用
dllm的DiffuGRPOTrainer;若要融入 VeOmni 原生分布式能力,最好重写为 VeOmni trainer。 - rollout 是否接 vLLM 类推理服务:dLLM sampler 不是标准 autoregressive decode,常规 vLLM token streaming/logprob API 不一定能直接承载。
- checkpoint 格式如何回到 HF:dFactory 训练后还要从 merged expert 拆回 separate expert,并复制 modeling 文件,这部分需要产品化。
- evaluation harness 如何适配:dLLM 的 perplexity、loglikelihood 和 generate_until 都要重新定义采样和评分过程。
相关工作¶
- MDLM:Masked Diffusion Language Modeling,提供 token mask diffusion 的基础训练目标。1
- LLaDA:把 diffusion language model 扩展到 LLM 规模,并展示 instruction following 和 reasoning 潜力。2
- BD3LM:用 block diffusion 在自回归与 diffusion 之间做结构折中。3
- dFactory:面向 LLaDA2 的 VeOmni 风格 SFT 工程参考。4
- dLLM / diffu-GRPO:提供 MDLM、BD3LM、sampler、SFT、GRPO 等教育和复现型代码。7
- VeOmni:可作为分布式训练底座,但当前文本主线仍以传统 causal SFT/RL 为默认假设。12
总结¶
dLLM 的本质是把语言建模从“前缀条件下的下一个 token”改为“带噪序列上的恢复任务”。这个变化在论文概念上很简洁,但落到 SFT 和 RL 代码会触发一串连锁变化:
- SFT 要新增 noising transform、masked labels 和可选 block attention。
- RL 要重写 sampler 和 logprob 定义,并保证 old/ref/current 的随机 mask 一致。
- 迁移到 VeOmni 时,训练底座可复用,但不能复用普通 causal SFT/RL 的 loss 假设。
因此,最稳妥的路线是:先做 full-attention MDLM SFT 最小闭环,再引入 block diffusion,最后做 diffu-GRPO。这条路径能把模型加载、数据变换、loss、采样、RL 概率定义逐层验证清楚。
参考文献¶
-
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models. ↩
-
inclusionAI/dFactory README, commit
92b6890. ↩ -
dFactory
tasks/dataset/data_transform.py,process_mdm_sft_example和sft_noise_transition. ↩ -
dFactory
tasks/train_llada2_bd.py定义 block diffusion mask;训练 step 拼接 noisy/clean input 并计算 loss。 ↩↩ -
ZHZisZZ/dllm README, commit
ca17675. ↩ -
dllm
dllm/core/trainers/mdlm.py,MDLMTrainer.compute_loss. ↩ -
dllm
dllm/core/trainers/bd3lm.py,BD3LMTrainer.compute_loss. ↩ -
dllm
dllm/pipelines/rl/grpo/trainer.py,DiffuGRPOConfig和_get_per_token_logps。 ↩↩ -
ByteDance-Seed/VeOmni README, commit
8ca09d7. ↩ -
VeOmni
veomni/trainer/text_trainer.py,TextTrainer. ↩↩ -
VeOmni
veomni/trainer/base.py,forward_backward_step和postforward. ↩↩ -
VeOmni
veomni/trainer/base_rl_trainer.py,BaseRLTrainer. ↩ -
VeOmni
veomni/arguments/arguments_types.py,DataArguments. ↩