VLM RL Evaluation Datasets
导言
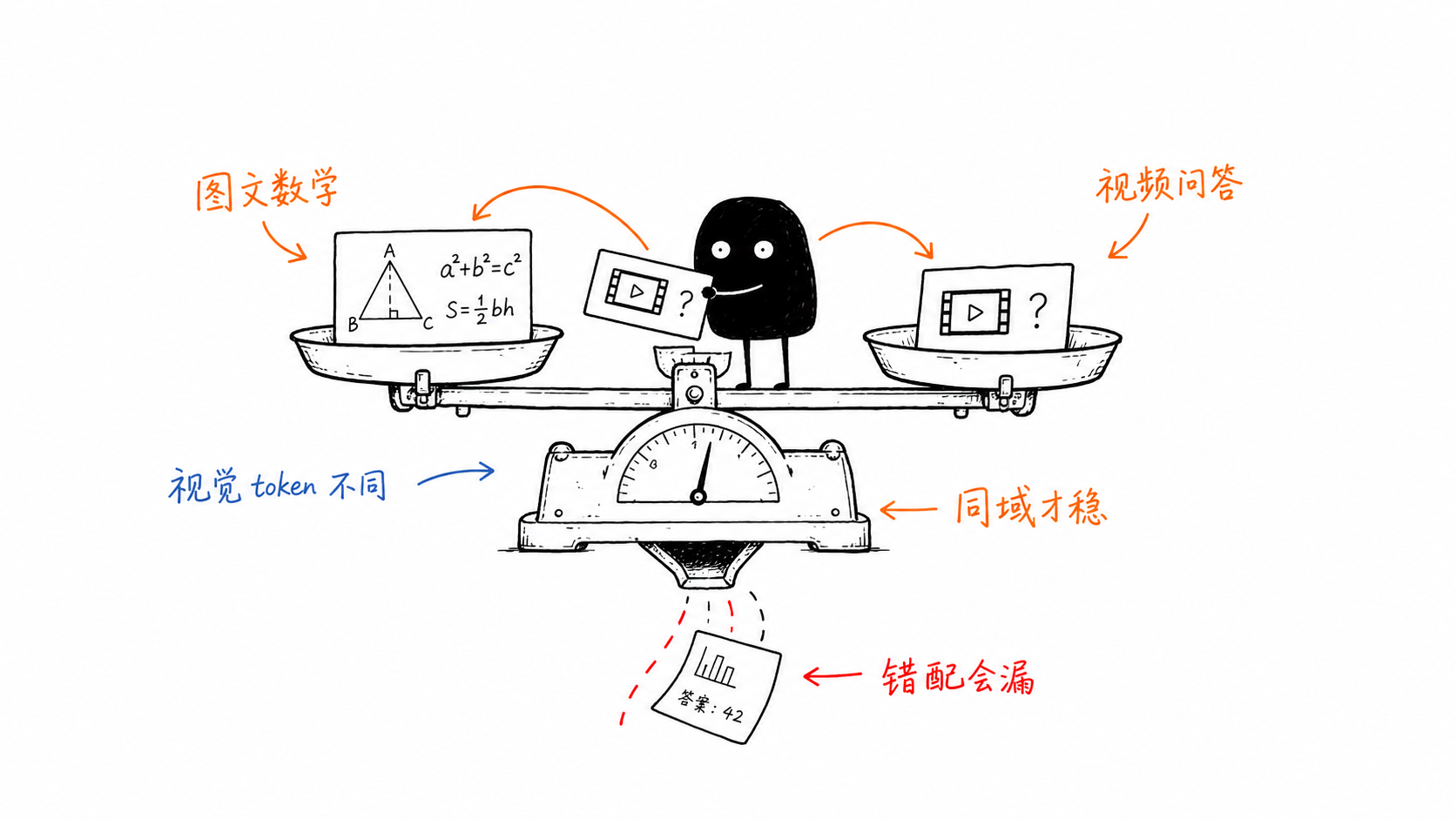
想用 AISBench 评测多模态 RL 后模型效果时,最容易误判的是把“多模态”当作一个整体类别。更精确的判断应该是:训练数据、奖励函数、输出格式和评测集必须在同一个能力域内闭合。
本文围绕 verl 当前常见的 Geo3K 多模态 RL 样例,以及新增的 TinyLLaVA-Video-R1-NextQA、multimodal-open-r1-8k-verified 两类数据,比较它们的规模、文本长度、模态、任务类型和 AISBench 评测匹配关系。
Core Judgment¶
结论先说:
- Geo3K 和
multimodal-open-r1-8k-verified更像同一类数据:单图 + 文本,主要考察几何、数学或图文推理,适合对齐 AISBench 中的MathVision、MMMU数学相关子域、MMStar等图文推理评测。 TinyLLaVA-Video-R1-NextQA是另一类数据:视频 + 文本,多选问答,偏事件、动作、时间关系和场景理解,应该对齐VideoBench、Video-MME这类视频理解评测。- 只看“都是多模态”是不够的。RLVR 类训练的收益通常最强地落在相同的:
- 模态:image / video / audio;
- 任务:几何、OCR、文档理解、视频事件问答、定位;
- 答案形态:数值、短文本、多选项、开放生成;
- verifier:正则抽取、exact match、VQA score、judge model;
- 输出契约:
\boxed{}、<answer>、自然语言答案。
不要把序列长度理解错
下表的平均长度主要统计文本字段,不包含 image patch token 或 video frame token。对 VLM 来说,真实 prompt_length 还取决于模型 processor、图像分辨率、视频采样帧数和视觉 token merge 策略,最终应以 verl 日志中的 prompt_length/mean、response_length/mean 为准。
Dataset Comparison¶
| Dataset | Scale | Modality And Task | Average Text Length | Reward / Answer Form | Match Judgment |
|---|---|---|---|---|---|
hiyouga/geometry3k / Geo3K |
3,002 total: train 2,101, validation 300, test 6012 | Single image + text geometry VQA. 原始题目多为短几何题、图中求角度/长度/面积。 | HF Viewer 全量统计:problem 平均约 58.0 chars,answer 平均约 3.8 chars。verl 预处理会额外追加约 214 chars / 44 cl100k tokens 的思考与 \boxed{} 指令。 |
verl 样例标记 ability="math",用规则 reward 匹配 ground_truth,要求最终答案放入 \boxed{}。3 |
适合图文数学/几何评测。不适合期待 VideoBench、TextVQA、DocVQA 上明显提升。 |
Zhang199/TinyLLaVA-Video-R1-training-data / NextQA |
5,496 条 0-30s NextQA RL 样本,另有 16 条 cold-start CoT 标注4 | Video + text multiple-choice QA. 题型集中在 why / what / how / where 等视频事件理解问题。 | 官方 JSONL 精确统计:prompt 平均 159.5 chars / 43.6 cl100k tokens,短答案平均 18 chars / 6 tokens,prompt+answer 平均 49.6 tokens,p95 60 tokens。16 条 cold-start 平均 prompt+answer 182.3 tokens。 | 短答案为 <answer>X</answer>;cold-start 含 <think> 和 <answer>。奖励适合多选 exact match 或 answer tag 抽取。 |
适合视频理解评测,如 AISBench VideoBench、Video-MME。不应作为 Geo3K/MathVision 提升的主要证据。 |
lmms-lab/multimodal-open-r1-8k-verified |
7,689 train examples5 | Single image + text reasoning. Dataset card 只给字段结构;从公开样例看,主体是图文数学/几何推理,带可验证答案。 | HF Viewer 全量统计:problem 平均 161.0 chars,solution 平均 672.3 chars,合计约 833.2 chars;solution 最长可到 28,539 chars,存在极长尾。 |
solution 通常包含 <think> 和 <answer>,更接近带思考链的 RL/SFT 混合材料;若用于 RL,需要明确只用 answer tag 做 reward,还是把 CoT 当参考。 |
和 Geo3K 最接近,更适合 MathVision / MMMU math / MMStar 这类图文推理评测。长度长尾要单独处理。 |
规模不是唯一变量
multimodal-open-r1-8k-verified 和 NextQA 的样本量都约为 Geo3K train split 的 2.6-3.7 倍,但两者提升的能力方向不同。更多样本不等于更通用的评测收益;如果 verifier 和评测任务错位,RL 可能只是强化输出格式或答案抽取习惯。
AISBench Mapping¶
AISBench 的数据集准备文档把开源评测分成 LLM、Multimodal、多轮对话等类别,其中多模态类包括 textvqa、videobench、MMMU、MMMU_Pro、InfoVQA、DocVQA、MMStar、Video-MME、OCRBench_v2、RealWorldQA、MathVision、RefCOCO 等。1
| RL Training Data | Best AISBench Evaluation Match | Medium Match | Weak Or Mismatched |
|---|---|---|---|
| Geo3K | MathVision,自定义 Geo3K eval,MMMU 数学/几何子域 |
MMStar,部分 RealWorldQA 几何/空间题 |
VideoBench、Video-MME、TextVQA、DocVQA、OCRBench_v2、RefCOCO |
multimodal-open-r1-8k-verified |
MathVision,Geo3K-style eval,MMMU 数学/图表推理子域 |
MMStar,部分 RealWorldQA |
视频、OCR、文档、定位任务 |
TinyLLaVA-Video-R1-NextQA |
VideoBench、Video-MME |
可能泛化到部分动态场景问答 | Geo3K、MathVision、OCR、文档理解、图像定位 |
换句话说,如果目标是证明“RL 后模型在 AISBench 上变强”,建议至少拆成两条实验线:
- Image Math RL 线:Geo3K +
multimodal-open-r1-8k-verified,评测MathVision、MMMUmath-like subset、MMStar,再加一个 TextVQA/DocVQA 作为负向迁移观测。 - Video QA RL 线:
TinyLLaVA-Video-R1-NextQA,评测VideoBench、Video-MME,再加 MathVision/Geo3K 作为跨域 sanity check。
Why Domain Match Matters¶
RLVR 的强化信号不是“抽象智能”本身,而是某个环境里可验证答案的反馈。对多模态模型来说,这个环境至少由四层组成:
- Perception Contract:图像、视频帧、OCR 文本、图表、几何图是否被同一种视觉处理路径编码。
- Reasoning Contract:模型是在做几何推导、常识问答、视频事件排序,还是文档字段抽取。
- Answer Contract:答案是
A/B/C/D、数值、短词、框选坐标,还是开放自然语言。 - Reward Contract:reward 是 exact match、VQA soft score、正则解析、judge model,还是任务专用 metric。
只要其中一层错位,训练和评测就可能出现下面几种现象:
- 格式提升但能力不升:模型更会输出
<answer>或\boxed{},但评测集需要自由文本或 OCR 字段。 - 推理提升但感知不升:图文几何 RL 可能改善数学解题模板,却不会自动改善视频动作识别。
- 短答案奖励过拟合:多选题 reward 容易把模型推向选项字母预测,未必提升开放问答。
- 视觉 token 分布错位:视频 RL 的真实 prompt length 常由帧数主导,和单图几何题的上下文预算不同。
Practical Plan¶
建议用一个小而清晰的矩阵验证,而不是把所有数据混成一锅:
| Experiment | RL Data | Eval Data | Purpose |
|---|---|---|---|
| Baseline | None | MathVision / MMMU / MMStar / VideoBench / Video-MME / TextVQA | 建立原始能力面,避免只看单一指标。 |
| Geo3K-only | Geo3K | MathVision + Geo3K-style eval | 验证 verl 官方样例线是否能稳定复现图文几何提升。 |
| Image-math mix | Geo3K + multimodal-open-r1-8k-verified |
MathVision / MMMU math / MMStar | 验证更大图文推理数据是否带来更稳的数学视觉收益。 |
| Video-only | TinyLLaVA-Video-R1-NextQA |
VideoBench / Video-MME | 验证视频事件问答收益,不和图文数学混淆。 |
| Cross-domain check | 每个 RL checkpoint | 非同域评测 | 检查是否出现遗忘、格式污染或无效迁移。 |
最小可行评测
如果算力有限,先不要同时训图文数学和视频 QA。更好的最小闭环是:Geo3K baseline -> Geo3K RL -> MathVision/MMMU 评测,以及 NextQA baseline -> NextQA RL -> VideoBench/Video-MME 评测。这两条线分别证明“图文数学”和“视频理解”,结论更干净。
Follow-Up Questions¶
后续真正影响实验可信度的问题主要有这些:
- verl 视频输入链路是否真的打通:
TinyLLaVA-Video-R1-NextQA是视频数据,不能只把<image>占位符当成单图处理。需要明确是传原视频、抽帧列表,还是预先编码帧。 - 视觉 token 预算如何记录:表中的文本长度很短,但视频帧会显著拉长真实 prompt。必须在训练日志里记录
prompt_length/mean、prompt_length/max和 clip ratio。 - answer parser 是否统一:Geo3K 用
\boxed{},NextQA 和 open-r1 数据用<answer>。如果评测端抽取逻辑不统一,指标会混入格式误差。 - CoT 是否参与 reward:
multimodal-open-r1-8k-verified有较长solution。如果只做 RLVR,reward 应聚焦 final answer;如果把 CoT 当监督,则更像 SFT/RFT 混合。 - AISBench 是否需要自定义 dataset config:AISBench 页面没有直接列 Geo3K 或 NextQA;若要做严格同源评测,可能需要按 AISBench 自定义数据集接口接入。
- 混合训练是否需要 curriculum:图文几何和视频问答混训时,reward 分布、视觉 token 长度和答案格式都不同,建议先单域收敛,再尝试按 domain tag 或比例采样混合。
Summary¶
你的理解大方向是对的:RL 数据集类型和评测类型越一致,越容易看到有效提升。但这里的“类型”不能只写成“多模态”,而要拆到更细:
Geo3K与multimodal-open-r1-8k-verified属于图文数学/几何推理,优先看 MathVision、MMMU math-like subset、MMStar。TinyLLaVA-Video-R1-NextQA属于视频问答,优先看 VideoBench、Video-MME。- 如果用 AISBench 做最终报告,最好同时放一个跨域负例,证明提升不是格式污染,而是真正在目标能力域内发生。
References¶
-
hiyouga/geometry3k Hugging Face dataset. 本文规模和字段长度参考 Hugging Face Dataset Viewer statistics endpoint:
https://datasets-server.huggingface.co/statistics?dataset=hiyouga/geometry3k&config=default&split=...。 ↩ -
lmms-lab/multimodal-open-r1-8k-verified. 本文字段长度参考 Hugging Face Dataset Viewer statistics endpoint:
https://datasets-server.huggingface.co/statistics?dataset=lmms-lab/multimodal-open-r1-8k-verified&config=default&split=train。 ↩